7.6 二分探索木
データの検索はコンピューターで最も頻繁に実行される操作かもしれない。効率的な検索を達成するために広く使われるデータ構造に探索木 (search tree) がある。
探索木の基本的なアイデアは難しくない。まず、検索されるデータが何らかの順序関係 ── 数値であれば通常の大小関係による順序、文字列に対しては辞書式順序など ── を持つことが仮定される。そしてデータは図 \(\text{7.1}\) のような枝分かれする「木」に配置される。この例では、節点で起こる枝分かれからは必ず二つ以下の新しい枝が生まれ、左の枝には節点に配置された数値より小さい数値が、右の枝には節点に配置された数値より大きい数値が配置される。この規則により、木の中にある数値の検索が簡単になる: 数値 \(g\) が存在するかどうかを知りたいときは、最も上の節点から初めて、注目している節点にある数値と \(g\) を比較する。もし一致するなら、\(g\) が木の中に存在するので「存在する」を返して検索を終える。\(g\) の方が小さいなら左の枝を進んで同じことを繰り返し、\(g\) の方が大きいなら右の枝を進んで同じことを繰り返す。最後に、もし進むべき枝が存在しないなら \(g\) は存在しないので「存在しない」を返して検索を終える。
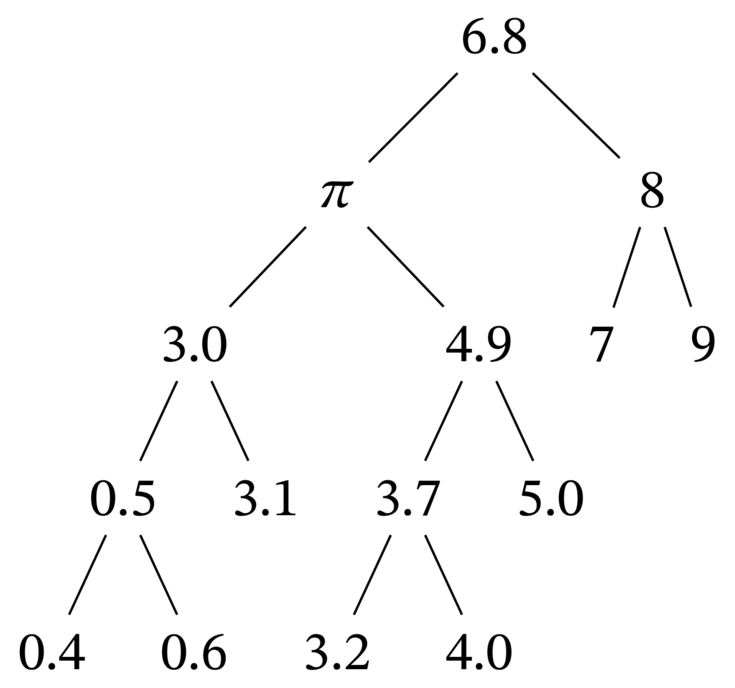
図 \(\text{7.1}\) の木で \(3.7\) を検索する例を示す。まず最も上の節点で \(3.7\) と \(6.8\) を比較する。\(3.7 < 6.8\) だから、左の枝を進んで次は \(3.7\) と \(\pi\) を比較する。\(\pi < 3.7\) だから、今度は右の枝を進む。続いて \(3.7\) と \(4.9\) を比較し、左に進み、そこで \(3.7\) を発見し、「存在する」を返して検索が終了する。
このようにデータを整理すると、データセットに含まれる全てのデータを走査することなく特定のデータを検索できる。実際、もし上から下までのパスの長さがどれも大きく変わらないなら、このパスの長さを \(n\) とするとき探索木全体は約 \(2^{n}\) 個のデータを保持できる。それぞれの検索はこういったパスの一つをたどるだけだから、単純に全データを走査するより指数的に高速なデータ検索が探索木によって可能になる。探索木が重宝される理由はここにある。
もちろん、探索木に含まれるパスが短くない可能性もある。図 \(\text{7.2}\) に示す極端な例では、全データの半分を含む長いパスが存在する。この木を使った検索は平均してこの長いパスを半分たどる必要があるので、指数的な高速化は達成されない。
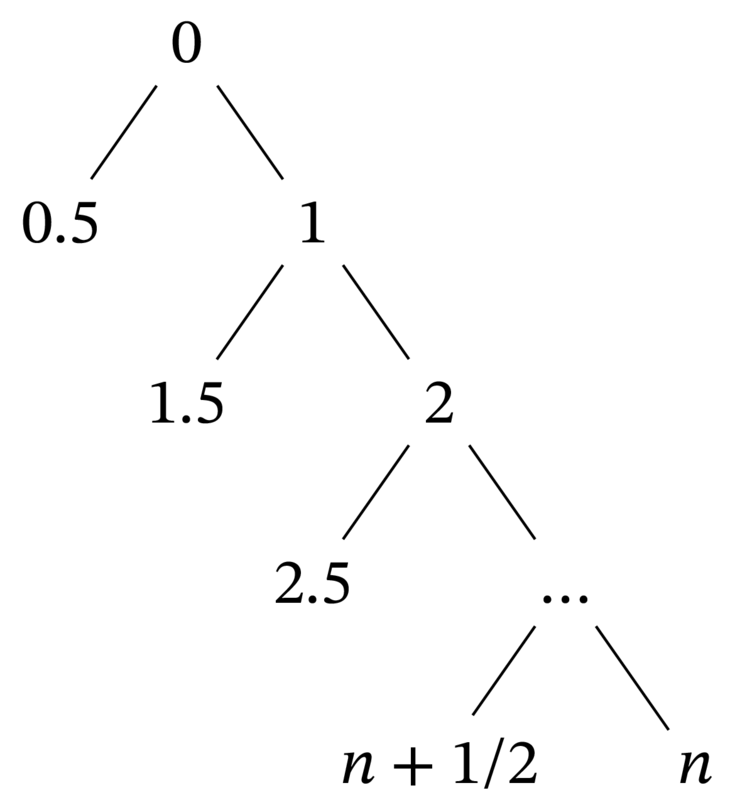
探索木を再帰的データ型として扱うと、木を管理するための様々な処理を単純な再帰的手続きとして表現できる。さらに、探索木やそれに対する手続きが満たす性質の証明で構造的帰納法という強力な証明技法が利用可能になる。本節では、上から下までの任意のパスがほぼ同じ長さを持つ探索木の簡潔な定義、その探索木にデータを追加・削除したときに性質を保つための手続きの厳密な定義を見る。
探索木に対して検索・挿入を行う鮮やかで効率的なアルゴリズムをこれから紹介するものの、本節で重要なのは基礎的なデータ型とそれに対する関数の単純な再帰的定義の例を示すことである。そのため本節には多くの数学的定義が含まれる: 数学的に定義できていないことに関する数学的に証明は存在しない。一通りの定義が完了したら、データ型の性質や手続きの正しさを再帰的データ型に対する手法、具体的には構造的帰納法で証明していく。
7.6.1 二股に分かれる木
これまでに示した図で数字が描かれるのは、枝分かれしない葉 (leaf)、または二股 (binary, two-way) に分かれて左右に枝が伸びる節点 (branch) のいずれかだった。二つより多くの枝に分かれる探索木は一部の応用で重要になるものの、最もよく使われるのは二股に分かれる二分木 (binary branching tree) であり、重要な考え方を説明するには二分探索木で十分である。そこで本節では二分木だけを考える。
コンピューター上のデータ構造 (あるいは数学的な概念) として木を表現する方法は数多く存在する。ここでは、表現の詳細を (あまり) 仮定せずに二分探索木を理解するために抽象的なアプローチを採用する。
最初に、言葉の使い方に関して誤解を招きかねない点を説明しておく。通常、「木」という言葉は図 \(\text{7.1}\) や図 \(\text{7.2}\) が示すような構造全体を意味する。しかし本節で使われる「木」は意味が異なり、図に表したとき最も上にある点 (ノード) を意味する。つまり木構造の頂上 (root) が「木」である。頂上より下にあるノードもまた「木」であり、これらは元の木の部分木 (subtree) と呼ばれる。
二分木 (binary branching tree) の集合 \(\text{BBTr}\) が存在することだけを仮定して議論を始めよう。二分木の重要な特徴に「葉かどうか」がある。二分木の表現がどんなものであったとしても、二分木が葉かどうかの判定は可能でなければならない。この判定を行う葉述語 (leaf predicate) を \(\text{leaf?}\) と表記する。つまり、二分木 \(T \in \text{BBTr}\) が葉なのは \(\text{leaf?}(T)\) が真のときである。葉全体からなる集合を \(\text{Leaves}\) と定義する:
葉でない木は左右に伸びる枝を持つ木である。二分木の任意の表現には、左右の枝を表現する方法が存在する。つまり、\(\text{BBTr}\) の葉でない要素を受け取って左または右の枝の先にある要素を返す選択関数 (selector function) \(\operatorname{left}\) と \(\operatorname{right}\) が存在する。この事実を形式的に記述するには、\(\text{Branching} ::= \text{BBTr} - \text{Leaves}\) と定め、次の全域関数が存在すると定める:
つまり \(T\) の左の枝の先には \(\operatorname{left}(T)\) があり、\(T\) の右の枝の先には \(\operatorname{right}(T)\) がある。
部分木
最初に示した探索木の例では、最も上にある数字から始まって下に向かうパスを考えた。こういったパスは節点で左右のどちらを選んだかを並べた列で記述できる。例えば図 \(\text{7.1}\) の木において、次の列が表すパスを考えよう:
このパスはラベル \(6.8\) の付いた全体の木 \(T_{6.8}\) から始まる。この列は右から順番に適用されるとすれば、パスが次に通過するのは \(\operatorname{left}(T_{6.8})\) つまり \(\pi\) のラベルが付いた部分木 \(T_{\pi}\) である。その後は \(\operatorname{left}(T_{\pi})\) つまり \(3\) のラベルが付いた部分木 \(T_{3}\) に移動する。最後に \(\operatorname{right}(T_{3})\) つまり \(3.1\) のラベルが付いた部分木に移動する。これは列 \(\text{(7.25)}\) が表すパスの終点にある部分木であり、次のように表せる:
一般に、選択関数の列 \(\overrightarrow{P}\) と \(T \in \text{BBTr}\) に対して、\(T\) から始まる \(\overrightarrow{P}\) が表すパスの終点にある部分木を \(\operatorname{subtree}_{T}(\overrightarrow{P})\) と表す。例えば先ほどの例で見たのは次の関係である:
なお、パス \(\overrightarrow{P}\) が \(T\) の葉を通り抜けるとき、終点にある部分木は存在しない。そのため例えば \(\operatorname{subtree}_{T_{6.8}}((\operatorname{left}, \operatorname{right}, \operatorname{right}))\) は未定義となる。なぜなら \(\operatorname{subtree}_{T_{6.8}}((\operatorname{right}, \operatorname{right}))\) が \(9\) のラベルが付いた葉であり、その左の枝の先にある部分木が存在しないからである。
これを形式的に定義するため、\(\operatorname{subtree}_{T}(\overrightarrow{T})\) をパスの長さに関して帰納的に定義する。まず記法を定める:
を、\(f\) で始まって \(\overrightarrow{P}\) の要素が続く列と定める。例えば列 \(\text{(7.25)}\) を \(\overrightarrow{P}\) とするとき、
は、次の \(4\) 要素列を表す:
\(\overrightarrow{P}\cdot f\) も同様に定義する。例えば
は、次の \(4\) 要素列を表す:
\(T \in \text{BBTr}\) を二分木、\(\overrightarrow{P}\) を選択関数が並んだ列とする。木 \(\operatorname{subtree}_{T}(\overrightarrow{P})\) は列 \(\overrightarrow{P}\) の長さに関して帰納的に次の規則で定義される:
-
ベースケース: \(\overrightarrow{P} = \lambda\) のとき、次のように定義される:
\[ \operatorname{subtree}_{T}(\overrightarrow{P}) ::= T \] -
構築ケース: 選択関数 \(f\) と選択関数の列 \(\overrightarrow{Q}\) を使って \(\overrightarrow{P} = f \cdot \overrightarrow{Q}\) と表せるとき、もし \(\operatorname{subtree}_{T}(\overrightarrow{Q})\) が定義されていて \(\text{Branching}\) に属するなら、次のように定義される:
\[ \operatorname{subtree}_{T}(\overrightarrow{P}) ::= f(\operatorname{subtree}_{T}(\overrightarrow{Q})) \]これ以外のとき \(\operatorname{subtree}_{T}(\overrightarrow{P})\) は定義されない1。
\(T\) から始まるパスの終点となる木全体の集合を \(\operatorname{Subtrs}(T)\) とする。正確に言えば:
木 \(T \in \text{BBTr}\) に対して、\(\operatorname{Subtrs}(T)\) を次のように定義する:
\(T\) と異なる部分木 (すなわち、木 \(T\) より「下」にある木) を、\(T\) の真部分木 (proper subtree) と呼ぶ。\(T\) の真部分木全体の集合を \(\operatorname{PropSubtrs}(T)\) と定義記する:
この定義から次の関係が分かる:
パスと部分木に関して、明らかであるものの明示的に表明しておく価値のある事実がいくつかある。まず、\(T\) の真部分木は \(T\) の右部分木または左部分木の部分木である:
全ての \(T \in \text{Branching}\) で次の関係が成り立つ:
また、全ての \(T \in \text{Leaves}\) で次の関係が成り立つ:
証明 (概要) \(T\) の任意の非空パスは最初で一歩で枝を右または左の部分木に移動し、以降の部分でその部分木内を移動する事実から分かる。
系 7.6.3 と等式 \(\text{(7.26)}\) から次の関係を得る:
二つ目の明らかな事実は「真部分木の部分木は真部分木」である:
もし \(S \in \operatorname{PropSubtrs}(T)\) かつ \(R \in \operatorname{Subtrs}(S)\) なら \(R \in \operatorname{PropSubtrs}(T)\) が成り立つ。
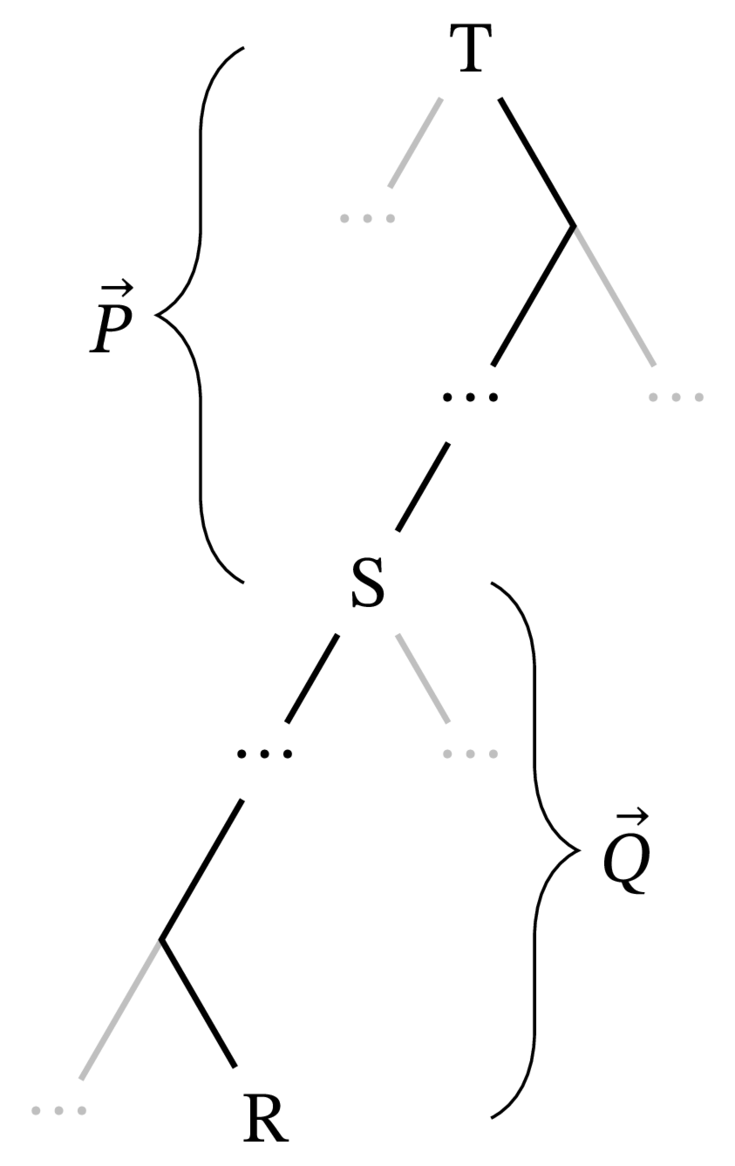
証明 (概要) \(T\) から \(T\) の真部分木 \(S\) までのパスを \(\overrightarrow{P}\) として、\(S\) から \(S\) の部分木 \(R\) までのパスとする (図 \(\text{7.3}\))。このとき二つのパスを連結2した \(\overrightarrow{Q} \cdot \overrightarrow{P}\) は \(T\) から \(R\) へのパスとなる。
7.6.2 二分木
これまで \(\text{BBTr}\) の要素を二分「木」と呼んできたものの、\(\text{BBTr}\) の抽象的な定義は木とは言えない奇妙な構造の存在を許している。例えば、自身と等しい真部分木を持つ「環状」の木を禁じる規則が存在しない。さらに、無限に大きい木の存在が許されている。例えば非負整数全体の集合を \(\text{BBTr}\) として、\(\operatorname{left}(n) ::= 2n+ 1\) および \(\text{right(n)} ::= 2n + 2\) と定めたとする。このとき \(\text{BBTr}\) は図 \(\text{7.4}\) に示す葉を持たない無限二分木を表す。
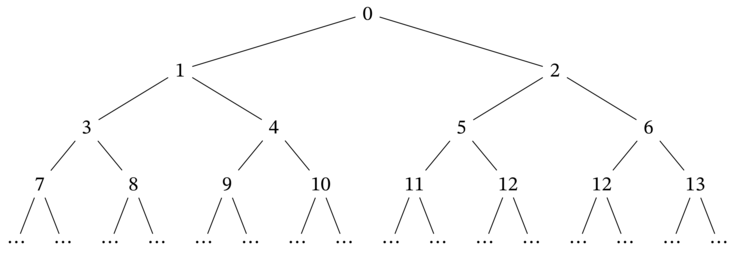
環状の木や無限の木の何が問題かと言えば、終端を持たないパスが生まれることである。これは検索処理が停止しない可能性を意味する。任意のパスは有限でなければならないと定めれば環状の木と無限の木が存在しなくなり、検索処理が停止することを保証できるようになる。
部分木で終わるパスは定義より有限なので、無限パスの定義ではそのことを明確にする必要がある:
木 \(T \in \text{BBTr}\) の無限パス (infinite path) とは、選択関数の無限列
であって、任意の接尾部 \(\overrightarrow{P_{n}} = (f_{n}, \ldots, f_{1}, f_{0})\) が次の条件を満たすものを言う:
問題は他にもある。無限パスが存在しない場合でも、\(\text{BBTr}\) に含まれる木が同じ部分木を共有する可能性がある。例えば右部分木と左部分木が同じ木が存在するかもしれない。この概念を定義しよう:
木 \(T \in \text{BBTr}\) が部分木を共有する (share subtrees) とは、次の条件を満たす二つの異なる有限列 \(\overrightarrow{P}\), \(\overrightarrow{Q}\) が存在することを言う:
-
\(\operatorname{subtree}_{T}(\overrightarrow{P})\) と \(\operatorname{subtree}_{T}(\overrightarrow{Q})\) が定義されている。
-
\(\operatorname{subtree}_{T}(\overrightarrow{P}) = \operatorname{subtree}_{T}(\overrightarrow{Q})\) が成り立つ。
部分木の共有は木をコンパクトに表現する上で非常に有用であるものの、木に対する要素の追加・削除、そして要素の検索をひどく複雑にする。そのため本節では部分木の共有も禁じる。
以上で、探索木で利用される見慣れた木 \(\text{FinTr}\) を定義する準備が整った:
一方で、同じような木を再帰的に定義する単純な方法も存在する:
再帰木 (recursive tree) の集合 \(\text{RecTr}\) は次の規則で再帰的に定義される。木 \(T \in \text{BBTr}\) に対して:
-
ベースケース: \(T \in \text{Leaves}\) のとき \(T\) は \(\text{RecTr}\) に属する。
-
構築ケース: \(T \in \text{Branching}\) のとき、もし \(\operatorname{left}(T) \in \text{RecTr}\) かつ \(\operatorname{right}(T) \in \text{RecTr}\) で両者が部分木を共有しない、すなわち
\[ \operatorname{Subtrs}(\operatorname{left}(T)) \cap \operatorname{Subtrs}(\operatorname{right}(T)) = \varnothing \]なら \(T\) は \(\text{RecTr}\) に属する。
\(\text{FinTr}\) と \(\text{RecTr}\) が等しいことを示すのが当面の目標となる。まずは全ての再帰木が有限だと示そう:
木 \(T \in \text{BBTr}\) の部分木の個数をサイズ (size) と呼び、\(\operatorname{size}(T)\) と表記する:
全ての再帰木は有限のサイズを持つ。
証明 \(T \in \text{RecTr}\) の定義に関する構造的帰納法で示す。
ベースケース: \(T \in \text{Leaves}\) のとき、\(T\) の部分木は \(T\) のみである。よって
が成り立つ。
構築ケース: \(T \in \text{Branching}\) のとき、\(L ::= \operatorname{left}(T)\) および \(R ::= \operatorname{right}(T)\) と定める。帰納法の仮定より \(L\) と \(R\) のサイズはいずれも有限である。よって等式 \(\text{(7.27)}\) より
も有限と分かる3。 ■
続いて一見すると意外な、非常に有用かつ (我々が思うに) 非常にクールな事実を証明する: 無限パスを持たず部分木を共有しない木は、再帰的に定義された木と同一である。この証明には多少の洞察が必要になる。
まず次の包含関係を証明する:
つまり、任意の再帰木 \(T\) は無限パスを持たず、かつ部分木を共有しないと示す。
証明 \(\text{RecTr}\) の定義に関する構造的帰納法で示す。
ベースケース: \(T \in \text{Leaves}\) のとき \(T\) は真部分木を持たない。よって \(T\) は無限パスを持たず、部分木を共有しない。
構築ケース: \(T \in \text{Branching}\) のとき \(\operatorname{left}(T)\) と \(\operatorname{right}(T)\) が定義され、いずれも \(\text{RecTr}\) に属する。帰納法の仮定より \(\operatorname{left}(T)\) と \(\operatorname{right}(T)\) は無限パスを持たず、かつ部分木を共有しない。
もし \(T\) が無限パス
を持つなら、最後の要素を取り除いた列
が \(f_{0}(T)\) の無限パスとなり、帰納法の仮定と矛盾する。よって \(T\) は無限パスを持たない。
続いて \(T\) が部分木を共有しないことを示す。\(T\) が無限パスを持たないので、\(\operatorname{left}(T)\) または \(\operatorname{right}(T)\) の部分木が \(T\) になることはない。つまり \(T\) は共有される部分木にならない。また、帰納法の仮定より \(\operatorname{left}(T)\) と \(\operatorname{right}(T)\) はそれぞれ内部に共有される部分木を持たない。後は \(\operatorname{left}(T)\) の部分木と \(\operatorname{right}(T)\) の部分木が一致する可能性だけが残されるが、これは \(\text{RecTr}\) の定義より不可能である。 ■
続いて、逆方向の包含関係を示す:
対偶を証明する。再帰木でない \(T \in \text{BBTr}\) を取り、\(T\) が無限パスを持つか、部分木を共有すると示せばよい。
証明 \(T \notin \text{RecTr}\) より \(T\) は葉でない。\(\operatorname{left}(T)\) と \(\operatorname{right}(T)\) に共通する部分木が存在するなら、それは \(T\) が共有する部分木であり、示したい主張が証明される。よって以降では \(\operatorname{left}(T)\) と \(\operatorname{right}(T)\) が共通の部分木を持たないと仮定する。このとき、もし \(\operatorname{left}(T)\) と \(\operatorname{right}(T)\) が両方とも \(\text{RecTr}\) に属するなら定義より \(T\) も \(\text{RecTr}\) に属するので、仮定 \(T \notin \text{RecTr}\) と矛盾する。つまり \(\operatorname{left}(T)\) と \(\operatorname{right}(T)\) のいずれかは \(\text{RecTr}\) に属さない。
よって選択関数 \(f_{0}\) を \(f_{0}(T) \notin \text{RecTr}\) を満たすように取れる。系 7.6.4 より \(f_{0}(T)\) の部分木は \(T\) の部分木なので、もし \(\operatorname{left}(f_{0}(T))\) と \(\operatorname{right}(f_{0}(T))\) が共通の部分木を持つなら、それは \(T\) が共有する部分木であり、主張が証明される。よって \(\operatorname{left}(f_{0}(T))\) と \(\operatorname{right}(f_{0}(T))\) は共通の部分木を持たず、前段落と同じ議論より \(\operatorname{left}(f_{0}(T))\) と \(\operatorname{right}(f_{0}(T))\) のいずれかは \(\text{RecTr}\) に属さない。よって選択関数 \(f_{1}\) を \(f_{1}(f_{0}(T)) \notin \text{RecTr}\) を満たすように取れる。
同様の議論で選択関数 \(f_{2}\) を \(f_{2}(f_{1}(f_{0}(T))) \notin \text{RecTr}\) を満たすように取れると示せる。以下同様に続けると、\(T\) は共有する部分木を持つか、無限パス
を持つ。 ■
7.6.3 再帰木の性質
木の再帰的な定義が手に入ったので、続いて木を引数に取る重要な基礎的関数をいくつか定義する。まず木のサイズを再帰的に定義する:
関数 \(\operatorname{recsize}\colon \text{RecTr} \to \mathbb{Z}^{+}\) は \(\text{RecTr}\) の定義に関して再帰的に定義される:
-
ベースケース: \(T \in \text{Leaves}\) のとき:
\[ \operatorname{recsize}(T) ::= 1 \] -
構築ケース: \(T \in \text{Branching}\) のとき:
\[ \operatorname{recsize}(T) ::= 1 + \operatorname{recsize}(\operatorname{left}(T)) + \operatorname{recsize}(\operatorname{right}(T)) \]
構造的帰納法による簡単な証明により、この定義が正しいことが示される。つまり:
全ての \(T \in \text{RecTr}\) で次の等式が成り立つ:
証明 \(\text{RecTr}\) の定義に関する構造的帰納法で示す。
ベースケース: \(T \in \text{Leaves}\) のとき、系 7.6.3 より \(\operatorname{Subtrs}(T) = \left\{ T \right\}\) なので、次が分かる:
構築ケース: \(T \in \text{Branching}\) のとき、帰納法の仮定より次が分かる:
等式 \(\text{(7.27)}\) からは、\(T \in \text{BBTr}\) なら
だと分かる。さらに今は \(T \in \text{RecTr}\) なので、等式 \(\text{(7.33)}\) の右辺にある三つの集合は共通要素を持たない。従って
を得る。よって次の等式が成り立つ:
■
同様に、再帰木の深さとは最も長いパスの長さを言う。形式的な定義を示す:
再帰的な定義は次の通りである:
再帰木 \(T \in \text{RecTr}\) の深さ (depth) は次の規則で再帰的に定義される: ベースケース: \(T \in \text{Leaves}\) のとき
構築ケース: \(T \in \text{Branching}\) のとき
次の補題 (問題 7.44) は構造的帰納法による簡単な証明で示せる:
全ての \(T \in \text{RecTr}\) で次の等式が成り立つ:
7.6.4 深さとサイズ
データを探索木に格納すると、検索にかかる時間を短縮できる。探索木を使ったデータの検索において、最も時間のかかる検索は探索木から葉への最も長いパスに対応する。ここから「データの個数と比べたとき、どの程度の検索時間が保証されるか?」という疑問が生まれる。簡単な解答は「\(n\) 個のデータが格納されるなら、少なくとも \(\log_{2} n\) 回の比較が必要になる検索が必ず生まれる」そして「検索に \(\log_{2} n\) 回より多い比較が必要になるデータが存在しないようにデータを配置する方法が存在する」である。これから見る二つの定理がこの解答を正当化する。
まず、再帰木のサイズと深さの間にある基本的な関係を証明する:
全ての \(T \in \text{RecTr}\) で次の不等式が成り立つ:
この不等式を簡単に理解・証明する方法がある: \(T \in \text{RecTr}\) で始まって葉で終わる二つのパスが異なる長さを持つとき、深さが \(T\) と同じでサイズが \(T\) よりも大きい再帰木が存在する ── 短い方のパスの「先」に新しい葉を二つ作ればよい。よって深さ \(d\) の再帰木の中で最もサイズが大きいのは、葉までのパスが全て同じ長さを持つ完全木 (complete tree) である。完全木には長さ \(1\) のパスが \(2\) 個あり、長さ \(2\) のパスが \(4\) 個ある。以下同様で、最も長い長さ \(d\) のパスは \(2^{d}\) 個ある。ここから次を得る:
構造的帰納法を使った証明も存在する。この証明では、実際に何を計算しているか分かりにくく、指数が絡む複雑な計算も必要になる。ただ、構造的帰納法を使うので洞察が必要なく、機械的に証明が完了する。さらに、この証明は木について何も知らない証明検証者 ── 人またはコンピュータープログラム ── でも検証できる。
証明 \(\text{RecTr}\) の定義に関する構造的帰納法で示す。
ベースケース: \(T \in \text{Leaves}\) のとき、次の等式が成り立つ:
構築ケース: \(T \in \text{Branching}\) のとき、\(\operatorname{recsize}\) の定義より
が分かる。\(d_{l}\), \(d_{r}\) を次のように定める:
等式 \(\text{(7.38)}\) から次を得る:
■
不等式 \(\text{(7.37)}\) の両辺に \(\log_{2}\) を適用すれば、データが \(n\) 個あるとき検索時間 (検索で必要になる比較の回数) が \(\log_{2} n - 1\) 回以上になるデータが少なくとも一つ存在すると分かる:
任意の再帰木 \(T \in \text{RecTr}\) で次の不等式が成り立つ:
一方で、検索時間が \(\log_{2} n - 1\) より長いデータが存在しないようにデータを格納することはできる。特定の木で始まって葉で終わる任意の二つのパスの長さが最大で \(1\) しか違わないとき、その木を完全平衡 (fully balanced) と呼ぶことにする。
\(B \in \text{RecTr}\) が完全平衡で深さが \(1\) 以上のとき、次の不等式が成り立つ:
証明 深さが \(d \geq 1\) の完全平衡な再帰木の中でサイズが最も小さいものは、深さ \(d\) に葉を \(2\) 個だけ持ち、他の全ての葉を深さ \(d-1\) に持つ。よって、完全平衡な再帰木のサイズの最小値は \(2^{d} - 1 + 2 = 2^{d} + 1\) である。 ■
任意の正の奇数 \(n\) に対して、サイズが \(n\) で深さが \(\log_{2} n\) 以下の再帰二分木 (\(\text{RecTr}\) の要素)が存在する ── 具体的には、任意の完全平衡な再帰二分木が条件を満たす。
7.6.5 AVL 木
木に保持されるデータが挿入と削除によって更新される中で木を完全平衡に保つには、全ての部分木の枝に変更が必要になる可能性がある ── データの更新が多ければ、この操作にかかる時間は高速な検索によって節約される時間を上回るだろう。完全平衡性を諦めつつ対数的な検索時間を達成する「一挙両得」なアプローチが望まれる。
完全平衡性を緩和した条件「任意の部分木の右側の深さと左側の深さの差が \(1\) 以下である」を満たす木を AVL 木と呼ぶ:
再帰木 \(T \in \text{RecTr}\) の葉でない任意の部分木 \(S \in \operatorname{Subtrs}(T)\) が次の条件を満たすとき、\(T\) を AVL 木 (AVL tree) と呼ぶ:
AVL 木全体の集合を \(\text{AVLTr}\) と表記する。
\(T\) が AVL 木のとき、次の不等式が成り立つ:
ここで \(\varphi\) は黄金比 (golden ratio) であり、次のように定義される:
証明 深さ \(d\) に関する強い数学的帰納法で示す。次の述語 \(P(d)\) を帰納法の仮定とする:
ベースケース: \(d = 0\) のとき \(T \in \text{Leaves}\) なので、次の等式が成り立つ:
よって \(P(0)\) は成り立つ。
帰納ステップ: \(T\) を深さ \(d + 1\) の AVL 木と仮定し、\(L ::= \operatorname{left}(T)\) および \(R ::= \operatorname{right}(T)\) と定める。\(L\) と \(R\) の深さは一方が \(d\) であり、もう一方は AVL 木の定義より \(d-1\) 以上である。強い帰納法の仮定より、\(L\) と \(R\) のサイズは一方が \(\varphi^{d}\) 以上で、もう一方が \(\varphi^{d-1}\) 以上である。よって次が分かる:
従って次の不等式が成立すれば \(P(d+1)\) も成立する:
\(\varphi > 0\) より、これは次の不等式と同値である:
\(\varphi^{2}\) を実際に計算すると
なので、不等式 \(\text{(7.41)}\) は成立する。よって \(P(d+1)\) も成立する4。 ■
不等式 \(\text{(7.40)}\) の両辺に \(\log_{2}\) を適用すれば、次の系を得る:
\(T\) が AVL 木のとき、次の不等式が成り立つ:
言い換えれば、AVL 木を使った検索は最適な検索時間と比べて最大でも \(1.44\) 倍しか遅くならず、全てのデータを走査するより指数的に高速なことに変わりはない。
7.6.6 数値ラベル
本節の冒頭で探索木の基本的な考え方、そして木のサイズと深さの関係が重要な理由を説明した。いよいよこれから探索木を再帰的データ型として再帰的に定義する。この定義があれば、検索関数の再帰的定義、そして構造的帰納法を使った性質の証明が可能になる。
探索木の任意の部分木には数値のラベルが付いている。抽象的には、これは次の全域関数の存在を意味する:
\(T\) に含まれるラベルの最小値と最大値を \(\operatorname{min}(T)\), \(\operatorname{max}(T)\) と表すことにする。正確に言えば、次のように定める:
探索木 (search tree) 全体の集合 \(\text{SrchTr}\) は次の規則で再帰的に定義される。\(T \in \text{BBTr}\) に対して:
-
ベースケース: \(T \in \text{Leaves}\) のとき、\(T\) は \(\text{SrchTr}\) に属する。
-
構築ケース: \(T \in \text{Branches}\) のとき、\(\operatorname{left}(T)\) と \(\operatorname{right}(T)\) が両方とも探索木で次の条件が満たされるなら、\(T\) は \(\text{SrchTr}\) に属する:
\[ \operatorname{max}(\operatorname{left} (T)) < \operatorname{num}(T) < \operatorname{min}(\operatorname{right}(T)) \]
探索木は定義より同じラベルを持った部分木を持てないので、部分木を共有しない。よって全ての探索木は再帰木 (\(\text{RecTr}\) の要素) である。
この定義を使えば、探索木から数値を検索する本節の冒頭で説明した単純な手続きを再帰的関数 \(\operatorname{srch}\) として定義できる。任意の探索木 \(T\) と数値 \(r\) に対する \(\operatorname{srch}(T, r)\) の値は、\(r\) が \(T\) に含まれるなら \(T\) で始まって \(r\) で終わるパスであり、\(r\) が \(T\) に含まれないなら \(T\) で始まって何らかの葉で終わるパスの先頭に \(\textbf{fail}\) を付けた列である。
関数
は次のように定義される:
-
\(r = \operatorname{num}(T)\) のとき
\[ \operatorname{srch}(T, r) ::= \lambda \] -
\(r \neq \operatorname{num}(T)\) のとき、\(\operatorname{srch}(T, r)\) は次の規則で探索木の定義 (7.6.24) に関して再帰的に定義される:
-
ベースケース: \(T \in \text{Leaves}\) のとき
\[ \operatorname{srch}(T, r) ::= \textbf{fail} \] -
構築ケース: \(T \in \text{Branching}\) のとき
\[ \operatorname{srch}(T, r) ::= \begin{cases} \operatorname{srch}(\operatorname{left}(T), r) \cdot \operatorname{left} & r < \operatorname{num}(T) \text{ のとき} \\ \operatorname{srch}(\operatorname{right}(T), r) \cdot \operatorname{right} & r > \operatorname{num}(T) \text{ のとき} \end{cases} \]
-
これでようやく、検索処理が正しい答えを返すという命題を厳密に表明できる:
任意の探索木 \(T\) と数値 \(r\) に対して、もし \(r \in \text{nums}(T)\) なら \(\operatorname{srch}(T, r)\) は選択関数の列であり、次の等式が成り立つ:
もし \(r \notin \text{nums}(T)\) なら、\(\operatorname{srch}(T, r)\) は何らかの列 \(\overrightarrow{P}\) を使って \(\textbf{fail} \cdot \overrightarrow{P}\) と表せる。
定理 7.6.26 は探索木の定義 (7.6.24) に関する構造的帰納法で簡単に証明できる。詳細は練習問題とする。
7.6.7 AVL 木に対する数値の挿入
数値 \(r\) を AVL 木 \(T\) に挿入する手続きは、検索処理と同様に AVL 木の定義に関して再帰的に定義できる。もし \(r\) が既に \(T\) に存在するなら、その事実は検索処理で発見でき、挿入処理は何もする必要がない。もし \(r\) が \(T\) に存在しないなら、挿入処理は \(\operatorname{num}(T)\) の要素との大小関係に応じて \(r\) を適切な位置に挿入する必要がある。より正確に言えば次の通りである。\(T\) の直下の部分木が \(A\), \(B\) であり、\(r\) を挿入すべき部分木が \(A\) だとする。\(A\) に \(r\) を再帰的に挿入した結果の AVL 木を \(S\) とすれば、\(S\) の部分木のラベルは \(r\) を除いて \(A\) の部分木のラベルと等しい。つまり、次の等式が成り立つ:
また、\(S\) の深さは \(\operatorname{depth}(A)\) または \(\operatorname{depth}(A) + 1\) である。
\(T\) と同じラベルを持ち、直下の部分木が \(S\) と \(B\) である木を \(N\) とする。このとき \(N\) は AVL 木 \(S\), \(B\) を直下の部分木に持つ探索木である。また、\(S\), \(B\) の部分木のラベルは \(r\) を除いて \(T\) の部分木のラベルに等しい。よって \(S\) の深さが \(\operatorname{depth}(B) + 1\) 以下なら \(N\) が \(T\) に \(r\) を挿入した結果の AVL 木となる。
残ったのは \(S\) の深さが \(\operatorname{depth} (B) + 2\) になるケースである。このケースでは、木の上部にあるいくつかの部分木を組み替える「回転 (rotation)」と呼ばれる操作を \(N\) に適用することで深さのバランスを取る。
回転操作を説明するために、変更される \(S\) の部分木に名前を付ける。\(d ::= \operatorname{depth}(B)\) と定めると、状況の設定から \(\operatorname{depth}(S) = d + 2\) が分かる。よって \(S\) の直下の部分木を \(R\), \(U\) とするとき、\(\operatorname{depth}(S)\) と \(\operatorname{depth}(R)\) の少なくとも一方は \(d + 1\) であり、両方とも \(d\) 以上である。\(S\) の直下の部分木の中で最も中心から遠いものを \(U\) と定める (図 \(\text{7.5}\))。
\(\operatorname{depth}(U) = d + 1\) のとき回転は単純になる。このとき \(N\) に回転を適用した結果は図 \(\text{7.6}\) に示す木 \(X\) である。
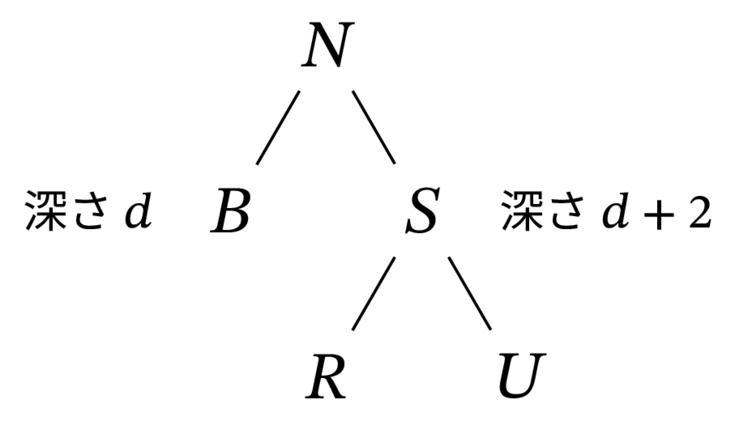
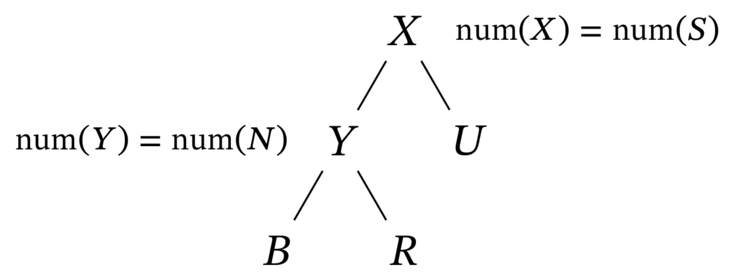
ここで \(X \in \text{RecTr}\) は「新しい」木 ── つまり \(X \notin \operatorname{Subtrs}(N)\) ── であり、\(S\) と同じラベルを持つ。\(Y\) も新しい木であり、こちらは \(N\) と同じラベルを持つ。ここから \(\text{nums}(X) = \text{nums}(N)\) を得る。また、\(\text{depth(Y)} = \operatorname{depth}(R) + 1\) で \(\text{depth(R)}\) は \(d\) または \(d + 1\) なので、\(\operatorname{depth}(Y)\) は \(d+1\) または \(d+2\) だと分かる。つまり \(Y\) の深さは \(U\) の深さと最大でも \(1\) しか変わらず、\(X\) と \(Y\) は部分木の深さが AVL 木の条件を満たす。容易に分かるように \(X\) は探索木でもあるので、回転の結果 \(X\) は AVL 木だと結論できる。また、次の等式が成り立つ:
\(\operatorname{depth}(U) = d\) のケースに対する回転も定義されるものの、これは練習問題 (問題 7.40) とする。この回転操作の存在を次の補題にまとめる:
関数
であって、次の条件を満たすものが存在する: AVL 木 \(B\), \(S\) と実数 \(r\) が
- \(\operatorname{depth}(S) = \operatorname{depth}(B) + 2\)
-
\(\operatorname{max}(B) < r < \operatorname{min}(S)\) または \(\operatorname{max}(S) < r < \operatorname{min}(B)\)
を両方とも満たすなら、次の条件が成り立つ:
- \(\text{nums}(\operatorname{rotate}(B, r, S)) = \text{nums}(B) \cup \left\{ r \right\} \cup \text{nums}(S)\)
- \(\operatorname{depth} (S) \leq \operatorname{depth}(\operatorname{rotate}(B, r, S)) \leq \operatorname{depth}(S) + 1\)
さらに、次の条件を満たす AVL 木の三要素5集合 \(S_{\text{new}}\), \(S_{\text{old}}\) が存在する:
- \(\text{Subtrs}(\operatorname{rotate}(B, r, S)) = (\operatorname{Subtrs}(B) \cup \operatorname{Subtrs}(S) \cup S_{\text{new}}) - S_{\text{old}}\)
続いて、\(\operatorname{insert}\) 関数を定義するには、任意の葉に探索木のラベル付け規則を満たすラベルを一つまたは二つ付けられるように定義を変更する必要がある (二分木の条件を緩和して、葉の親に限って直下の部分木が一つでも構わないと定めると考えることもできる)。葉に追加される追加のラベルは、新しいラベル付けを決定するときにバッファとして利用される。このバッファが存在しないと、単一の挿入または削除によって全ての部分木に対するラベルが更新される可能性が生まれる (問題 7.42)。
関数
は次のように定義される:
「\(r = \operatorname{num}(T)\)」または「\(T \in \text{Leaves}\) が二つのラベルを持ち \(r \in \text{nums}(T)\)」のとき
それ以外のとき、\(\operatorname{insert}(T, r)\) は次の規則で探索木の定義 (7.6.24) に関して再帰的に定義される:
ベースケース: \(T \in \text{Leaves}\) のとき、さらに二つの場合に分かれる:
-
\(T\) がラベルを一つ持つなら、\(\operatorname{insert}(T, r)\) は二つの値 \(r\), \(\operatorname{num}(T)\) を値にラベルに持つ葉と定義される。
-
\(T\) がラベルを二つ持つなら、\(\operatorname{insert}(T, r)\) は三つの値 \(\left\{ r \right\} \cup \operatorname{num}(T)\) をラベルに持つ深さ \(1\) の探索木と定義される。
構築ケース: \(T \in \text{Branching}\) のとき、さらに二つの場合に分かれる:
-
\(r > \operatorname{num}(T)\) のとき: \(S ::= \operatorname{insert}(\operatorname{right}(T), r)\), \(B ::= \operatorname{left}(T)\) と定める。そして \(N\) を「新しい」木とする。つまり
\[ N \notin \operatorname{Subtrs}(S) \cup \operatorname{Subtrs}(B) \]を取る。ただし、\(N\) は次の条件を満たすとする:
\[ \operatorname{num}(N) = \operatorname{num}(T) \tag{7.45}\]\[ \operatorname{right}(N) = S \hspace{41pt} \tag{7.46}\]\[ \operatorname{left}(N) = B \hspace{30pt} \tag{7.47}\]その上で、次のように定義する:
\[ \begin{aligned} \operatorname{insert}(T, r) &::= N & (\operatorname{depth}(S) \leq \operatorname{depth}(B) + 1 \text{ のとき}) \\ \operatorname{insert}(T, r) &::= \operatorname{rotate}(B, r, S) & (\operatorname{depth}(S) = \operatorname{depth}(B) + 2 \text{ のとき}) \end{aligned} \] -
\(r < \operatorname{num}(T)\) のとき: 一つ目の場合と同様とする。ただし \(\operatorname{left}\) と \(\operatorname{right}\) を逆転させる。
\(\operatorname{insert}(T, r)\) が正しいことを示す形式的な定理を次に示す。挿入処理の正しさに加えて、\(T\) に存在せず \(\operatorname{insert}(T, r)\) だけに存在する部分木の個数は最大で \(T\) の高さの \(3\) 倍であることも言える。つまり検索と同様に、挿入処理にかかる時間はデータの個数に関して対数的にしか増加しない。
\(T\) を AVL 木、\(r \in \mathbb{R}\) とする。このとき \(\operatorname{insert}(T, r)\) は AVL 木であり、次の関係が成り立つ:
- \(\text{nums}(\operatorname{insert}(T, r)) = \left\{ r \right\} \cup \text{nums}(T)\)
- \(\operatorname{depth}(T) \leq \operatorname{depth}(\operatorname{insert}(T, r)) \leq \operatorname{depth}(T) + 1\)
さらに、AVL 木からなる要素数が \(3 \cdot 1.44 \log_{2}\operatorname{size}(T)\) 以下の集合 \(S_{\text{new}}\), \(S_{\text{old}}\) が存在して、次の等式が成り立つ:
AVL 木からデータを削除する手続きも同様のアプローチから得られる (問題 7.43)。
-
構築ケースは「もし \(\overrightarrow{P} = \overrightarrow{Q} \cdot f\) で \(T \in \text{Branching}\) なら \(\operatorname{subtree}_{T}(\overrightarrow{P}) ::= \operatorname{subtree}_{f(T)}(\overrightarrow{Q})\)」でも構わない。 ↩︎
-
パスの連結は右から左に適用されると定める。例えば \(\overrightarrow{Q} \cdot \overrightarrow{P}\) は最初に \(\overrightarrow{P}\) をたどり、それから \(\overrightarrow{Q}\) をたどる。 ↩︎
-
不等式 \(\text{(7.29)}\) は実際には等式である。以降で等式 \(\text{(7.34)}\) が成り立つことを見る。 ↩︎
-
訳注: 黄金比 \(\varphi\) は二次方程式 \(1 + x = x^{2}\) の解の一つである。 ↩︎
-
訳注: ここで考えた \(\operatorname{depth}(U) = d + 1\) のケースでは新しい木が \(2\) 個導入されるものの、問題 7.40 で考える \(\operatorname{depth}(U) = d\) のケースでは新しい木が \(3\) 個導入される。 ↩︎