21.2 グラフ上のランダムウォーク
ワールドワイドウェブ上に張られるハイパーリンクの構造は有向グラフで記述できる。ウェブページが頂点となり、頂点 \(x\) から頂点 \(y\) への有向辺は \(x\) から \(y\) にハイパーリンクがあるとき、かつそのときに限って存在する。例えば、MIT の 6.042 講義「情報科学のための数学」に関連するウェブページと、それらの間のリンクは図 \(\text{21.3}\) に示す構造を持つ。

ウェブ全体を表す有向グラフは途方もなく巨大であり、数兆個の頂点を持つ。この有向グラフをウェブグラフ (web graph) と呼ぶことにする。スタンフォード大学の学生だった Larry Page と Sergey Brin は 1995 年、このウェブグラフの構造が検索エンジンを作る上で非常に有用であることに気が付いた。当時のドキュメント検索プログラムは非常に単純で、基本的な動作は「ユーザーが入力した単語 (検索語) を含むドキュメントを全て返す」というものだった。ドキュメントで検索語が登場する位置や回数によって検索結果に関連性を表すスコアが割り当てられる場合もあった。例えば検索語が \(100\) 回使われているドキュメントの関連性スコアは高くなる。
このアプローチは検索語を含むドキュメントが多くない場合には問題なく動作する。しかしウェブ検索では、検索対象のドキュメントの個数は数兆、典型的な検索語を含むサイトの個数は数百万にも及ぶ。例えば 2012 年 5 月 2 日現在、Google で「"Mathematics for Computer Science" text」を検索すると \(482{,}000\) 件もの検索結果が表示される! どのページに目を通すべきだろうか? 先述のアプローチだと、例えば先頭に「Mathematics Mathematics \(\ldots\) Mathematics」と \(200\) 回書かれているページのスコアが大きくなる ── しかし、このページに大きな価値があるとは思えない。ウェブにはユーザーを「釣る」ために特定の単語を何度も繰り返し含んだ無意味なページが山ほど存在する。
Google の莫大な資産の一部は、検索結果の上位に広告を表示させる権利を販売して得られた収益である。もし検索語の登場頻度を操作するだけで検索結果の上位に好きなページを表示させられるとしたら、この権利には大きな価値が産まれない。Google の広告が購入されるのは、Google がユーザーの望むページを見つける手法が一貫して優れているためである。例えば、先ほどの検索語で検索すると 6.042 講義のページ1が最上位に表示されることからも Google 検索の正確性が分かる。
どうして Google は \(482{,}000\) 個の検索結果から本書のページを選択できたのだろうか? ── なぜなら、ウェブグラフの構造を使えば最も重要なページを高い確率で発見できることを 1995 年に Larry と Page が見抜いたからである。
21.2.1 不十分なページランク
ページ間のリンクを表す有向グラフが与えられたとき、最上位に表示すべきページ (頂点) はどうすれば発見できるだろうか? 検索語を含むページが以下の図に示す有向グラフの構造を持つとしよう。この場合、直感的には \(x_{2}\) を最上位に表示すべきだと感じる。なぜなら \(x_{2}\) に向けてリンクを張っているページが多くあるからである。ここから一つ目のアイデアが示唆される: 頂点 \(x\) のページランク (page rank) を入次数 \(\operatorname{indeg}(x)\) と定義して、このページランクが最も大きいページを最上位に表示させればよい。リンクは「投票」を表し、票を多く集めたページは価値が高いと解釈する。

しかし残念ながら、このアイデアにはいくつか問題がある。特定のページを検索結果の上位に表示させたいと考えている状況を想像してほしい。このとき、そのページにリンクを張るダミーページを大量に作成すれば、上記のページランクを任意に大きくできる:
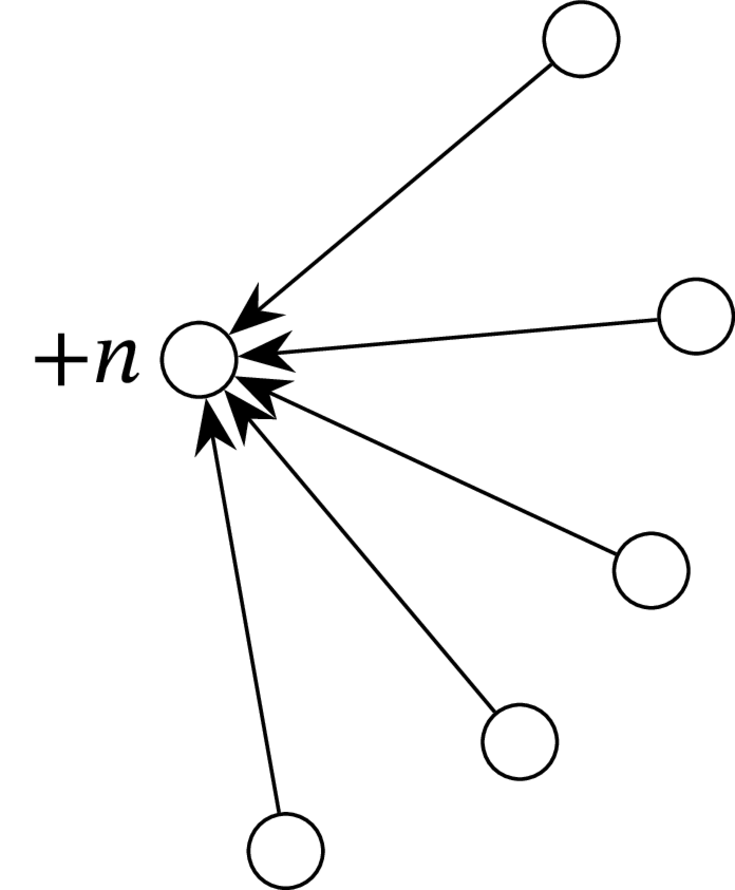
問題は他にもある ── 各ページの扱いが公平でない。具体的には、大量のリンクを持つページは検索結果に大きな影響を与える:
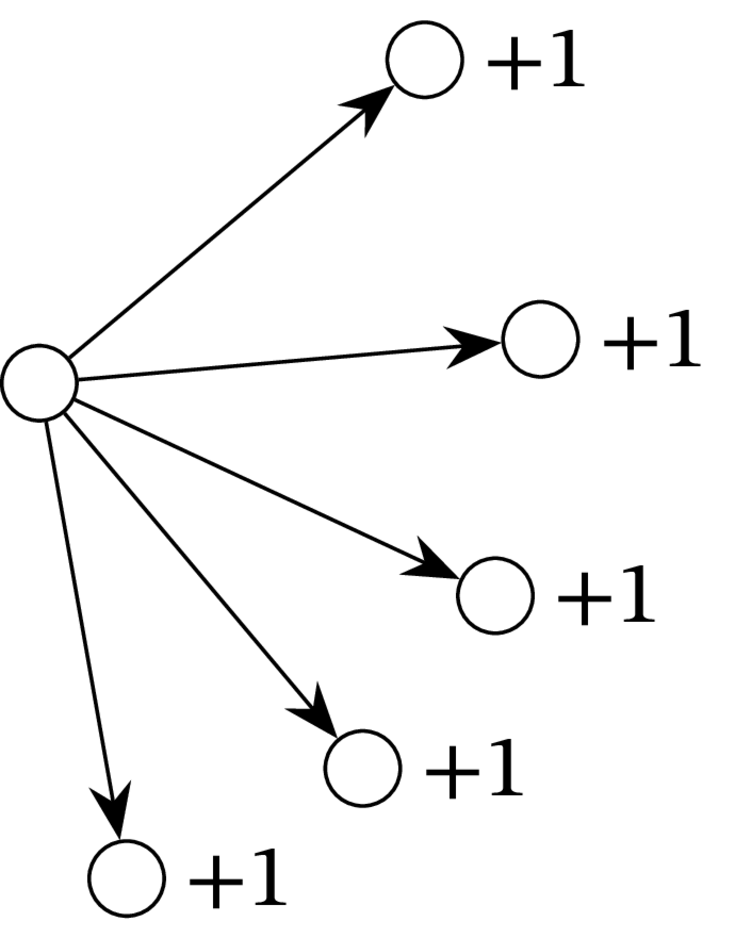
つまり、このアプローチによるランク付けは「早く行って何度も投票する」ページを優遇する。そのような検索エンジンの広告枠に購入するだけの価値は生まれないだろう。何もしないよりはマシかもしれないが、数十億ドルを稼ぐには明らかに十分でない。
21.2.2 ウェブグラフ上のランダムウォーク
Sergey と Larry はこのアイデアをさらに発展させ、いくつかの改善を考案した。彼らはページの入次数そのものではなく、ウェブグラフ上で長い間ランダムウォークをしたとき各ページに行きつく確率に注目した。より正確に言えば、彼らはウェブを利用するユーザーの行動を「ページに含まれるリンクを等しい確率でクリックしてページを移動する」とモデル化した上で、ユーザーが見ている確率の高いページが価値の高いページだと考えた。例えば、もしユーザーがページ \(x\) を見ていて \(x\) にリンクが \(3\) 個含まれるなら、それぞれのリンクは確率 \(1/3\) でクリックされる。一般化すれば、ウェブグラフの任意の有向辺 \(\langle x \to y \rangle\) には事象「ページ \(x\) にいる」で条件付けられた確率が割り当てられる:
こうすれば、ユーザーの行動はウェブグラフ上のランダムウォークに等しくなる。
特定のページ \(y\) に移動する確率は \(y\) に向かう有向辺に関する和を考えれば計算できる。つまり次の関係が成り立つ:
例えば、先ほど示したウェブグラフでは次の等式が成り立つ:
この等式は「\(x_{7}\) は自身の確率の半分を \(x_{4}\) に送り、\(x_{2}\) は自身の確率の全てを \(x_{4}\) に送る」と解釈できる。
このモデルでは捉えられない実際のユーザーの行動が一つある: ユーザーは外向きのリンクを一切持たないページを見ることがある。現在のモデルだと、このユーザーは他のページに移動できない。しかし実際のユーザーは同じページを永遠に見つめ続けるのではなく、リンクをクリックする以外の手段で関係ないページを開くだろう。さらに言えば、ユーザーが「行き止まり」でないページを見ていたとしても、リンクを何度もたどるうちに目当ての情報が得られないと判断して関係ない他のページを開くかもしれない。
この行動をモデル化するため、Sergey と Larry は超頂点 (supervertex) と呼ばれる特別な頂点をウェブグラフに追加し、超頂点と任意の頂点を両方向の有向辺で結んだ (超頂点には自己ループが追加される)。このときウェブグラフは強連結となる。この上で超頂点から他の頂点に向かう有向辺に等しい確率を割り当てれば、ユーザーが現在のページに含まれるリンクを利用しないで全く別のページに移動する行動を超頂点への移動 (そして続く超頂点からの移動) としてモデル化できる。
ページがリンクを持たないなら、そのページから超頂点へ向かう有向辺には確率 \(1\) が割り当てられる。ページがリンクを持つ場合は、そのページから超頂点へ向かう有向辺には任意に選ばれた特定の確率が割り当てられる。オリジナルのページランクでは、この確率が \(0.15\) に設定された。つまり、出次数 \(n\) が \(1\) 以上の頂点には \(0.15\) の確率が割り当てられた超頂点へ向かう有向辺が付け足され、元から存在する \(n\) 本の有向辺には \(0.85/n\) の等しい確率が割り当てられる。
21.2.3 ページランクの定常分布
このように改善されたページランクの計算では「ウェブグラフの定常分布 (stationary distribution) を求める」が基本的なアイデアとなる。
各頂点に確率を割り当てることを考える。直感的に言えば、特定の頂点に割り当てられる確率はウェブグラフ上を十分長い間ランダムウォークした点がその頂点にいる確率に等しい。この確率の割り当てを \(d\) とすれば、\(d\) が確率であるためには次の等式が成り立つ必要がある:
有向辺に確率が割り当てられた有向グラフの頂点に対する確率の割り当て \(d\) が定常分布 (stationary distribution) とは、全ての頂点 \(x\) で次の等式が成り立つことを意味する:
Sergey と Larry はページランクを定常分布として定義した。その値を計算するには、全ての頂点 \(x\) に対して次の等式を満たす非負実数 \(\operatorname{Rank}(x)\) を求めればよい:
これは以前に示した直感的な数式 \(\text{(21.13)}\) に対応する。また、等式 \(\text{(21.14)}\) に対応する追加の制約も満たされる必要がある:
これは線形方程式系である: 求めるべき値 \(\operatorname{Rank} (x)\) は頂点と同じく \(n\) 個あり、等式 \(\text{(21.15)}\), \(\text{(21.16)}\) は \(\operatorname{Rank} (x)\) が満たす \(n + 1\) 個の線形方程式を定める。制約 \(\text{(21.16)}\) が必要なのは、全ての頂点 \(x\) に対して \(\operatorname{Rank} (x) ::= 0\) とする意味のない割り当てが制約 \(\text{(21.15)}\) を満たすので、これを除外するためである。
Sergey と Larry は頭の切れる男たちだった。彼らはどんなときでも意味のある解を出力するページランク計算アルゴリズムを生み出した。強連結な有向グラフでは定常分布が一意 (問題 21.12) であり、彼らの考案した超頂点の追加処理によって強連結性は保証される。さらに、任意の頂点から (その頂点の確率が \(1\) の確率分布から) 開始してランダムウォークを長く続けると、確率分布が定常分布に近づいていくことも示せる。超頂点を持たない一般の有向グラフはいずれの性質も持たない点に注意してほしい: 定常分布が一意とは限らず、たとえ一意でもランダムウォークの開始頂点によっては確率分布が定常分布に収束しない可能性がある (問題 21.8)。
数兆個のウェブページを頂点とする有向グラフは保持しておくだけでも大仕事となる。これは 2011 年に Google が太陽光発電所に \(\$168{,}000{,}000\) を投資した理由でもある ── Google のサーバーが 2011 年に消費した電力は標準的な家庭 \(200{,}000\) 軒分に相当する。Larry と Sergey が検索エンジンに付けた名前 Google の由来は \(10^{100}\) と定義される定数グーゴル (googol) と呼ばれる定数であり、ウェブグラフが巨大である事実を表すために選ばれたと言われている。
ともかく、これで \(378{,}000\) 件の検索結果の中で本書が最上位に表示された理由が理解できただろう。本書は他大学の講義でもよく利用されており、そういった講義のウェブページには MIT Open Course Ware の「情報科学のための数学」ページにリンクを持つ。大学のサイト自体も適切なサイトと評価されている場合が多いので、本書はウェブグラフで高く評価されているのだと思われる。
-
理由は不明だが、なぜか最上位に表示されるのは Princeton 大学のウェブサイトにアーカイブされた本書の初期バージョンだった。MIT Open Courseware サイトにある 2010 年春学期バージョンは \(4\) 位と \(5\) 位に表示された。 ↩︎