練習問題
問題 7.1
順序付き二分木 (ordered binary tree) の集合 \(\text{OBTr}\) は次の規則で再帰的に定義される:
-
ベースケース: \(\langle \textbf{leaf} \rangle \in \text{OBTr}\)
-
構築ケース: \(R\) と \(S\) が順序付き二分木のとき \(\langle \textbf{node}, R, S \rangle \in \text{OBTr}\)
\(T \in \text{OBTr}\) に対して、\(T\) に含まれる \(\textbf{node}\) ラベルの個数を \(n_{T}\) と定め、\(\textbf{leaf}\) ラベルの個数を \(l_{T}\) と定める。
全て \(T \in \text{OBTr}\) で次の等式が成り立つことを構造的帰納法で示せ:
問題 7.2
文字列の再帰的定義 (7.1.1) に関する構造的帰納法を使って、文字列の連結が結合的 (associative) だと証明せよ。つまり、全ての文字列 \(r, s, t \in A^{\ast}\) で次の等式が成り立つと示せ:
問題 7.3
文字列 \(s\) を逆に読んだ文字列を \(s\) の反転 (revsersal) と呼び、\(\operatorname{rev}(s)\) と表す。例えば \(\operatorname{rev}(\text{abcde}) = \text{edcba}\) が成り立つ。
-
文字列の再帰的定義 (7.1.1) と文字列の連結の再帰的定義 (7.1.3) を利用して、\(\operatorname{rev}(s)\) の簡単な再帰的定義を示せ。
-
全ての文字列 \(s, t \in A^{\ast}\) で次の等式が成り立つと示せ:
\[ \operatorname{rev}(s \cdot t) = \operatorname{rev}(t) \cdot \operatorname{rev}(s) \tag{7.49}\]文字列の連結が結合的である (問題 7.2) ことを仮定してよい。つまり、全ての文字列 \(r, s, t \in A^{\ast}\) で次の等式が成り立つ事実を証明せずに使って構わない:
\[ (r \cdot s) \cdot t = r \cdot (s \cdot t) \]
問題 7.4
The Elementary 18.01 Functions (\(\text{F18}\)) は実数を引数に取る関数の集合であり、次の規則で再帰的に定義される:
ベースケース:
-
恒等関数 \(\operatorname{id}(x) ::= x\) は \(\text{F18}\) に属する。
-
任意の定数関数は \(\text{F18}\) に属する。
-
サイン関数は \(\text{F18}\) に属する。
構築ケース: \(f, g \in \text{F18}\) のとき、次に示す関数も \(\text{F18}\) に属する:
-
\(f + g\), \(fg\), \(2^{g}\)
-
逆関数 \(f^{-1}\)
-
合成 \(f \circ g\)
-
\(1/x\) が \(\text{F18}\) に属すると示せ。
注意: \(1/x = x^{-1}\) と恒等関数 \(\operatorname{id}(x)\) の逆関数 \(\operatorname{id}^{-1}\) を混同しないように注意せよ。\(\operatorname{id}^{-1}\) は \(\operatorname{id}\) に等しい。
-
\(\text{F18}\) の定義に関する構造的帰納法を使って、\(\text{F18}\) が微分を取る操作に関して閉じていることを示せ。つまり、関数 \(f\) が \(\text{F18}\) に属するとき \(f^{\prime} = df/dx\) も \(\text{F18}\) に属することを証明せよ。構築ケースに関しては最も興味深い場合を二つか三つ示せば十分である。それ以外の場合は飛ばしてよい。
問題 7.5
偶数全体からなる集合 \(E\) の単純な再帰的定義を次に示す:
-
ベースケース: \(0 \in E\)
-
構築ケース: \(n \in E\) のとき \(n + 2 \in E\) かつ \(-n \in E\)
これと同様の単純な再帰的定義で次の集合を定義せよ:
- \(S ::= \left\{ 2^{k}\,3^{m}\,5^{n} \in \mathbb{N} \; | \; k, m, n \in \mathbb{N} \right\}\)
- \(T ::= \left\{ 2^{k}\,3^{2k + m}\,5^{m + n} \in \mathbb{N} \; | \; k, m, n \in \mathbb{N} \right\}\)
- \(L ::= \left\{ (a, b) \in \mathbb{Z}^{2} \; | \; (a - b) \text{ は } 3 \text{ の倍数} \right\} \)
あなたが \(\text{(c)}\) で解答した定義が定める集合を \(L^{\prime}\) とする。もし解答が正しければ \(L^{\prime} = L\) が成り立つものの、解答が間違っている可能性もある。正しさを確認してみよう。
-
\(L^{\prime}\) の定義に関する構造的帰納法で次の包含関係を示せ:
\[ L^{\prime} \subseteq L \] -
さらに次の包含関係を示すことで、解答が正しいことを確認せよ:
\[ L \subseteq L^{\prime} \] -
[スキップ可] \(L\) の曖昧でない再帰的定義を見つけよ。
問題 7.6
葉のラベルが集合 \(L\) の要素である二分木を表す再帰的データ型 \(\text{binary-2PG}\) を次の規則で再帰的に定義する:
-
ベースケース: 任意のラベル \(l \in L\) に対して
\[ \langle \textbf{leaf}, l \rangle \in \text{binary-2PG} \] -
構築ケース: \(G_{1}, G_{2} \in \text{binary-2PG}\) のとき
\[ \langle \textbf{bintree}, G_{1}, G_{2} \rangle \in \text{binary-2PG} \]
\(G \in \text{binary-2PG}\) のサイズ (size) \(|G|\) は次の規則でこの定義に再帰的に定義される:
-
ベースケース: 任意の \(l \in L\) に対して
\[ |\langle \textbf{leaf}, l \rangle| ::= 1 \] -
構築ケース: \(G_{1}, G_{2} \in \text{binary-2PG}\) のとき
\[ | \langle \textbf{bintree}, G_{1}, G_{2} \rangle | ::= |G_{1}| + |G_{2}| + 1 \]
\(G \in \text{binary-2PG}\) の例を図 \(\text{7.7}\) に示す。この \(G\) のサイズは \(7\) で、ラベルの集合は \(\left\{ \text{win}, \text{lose} \right\}\) である。
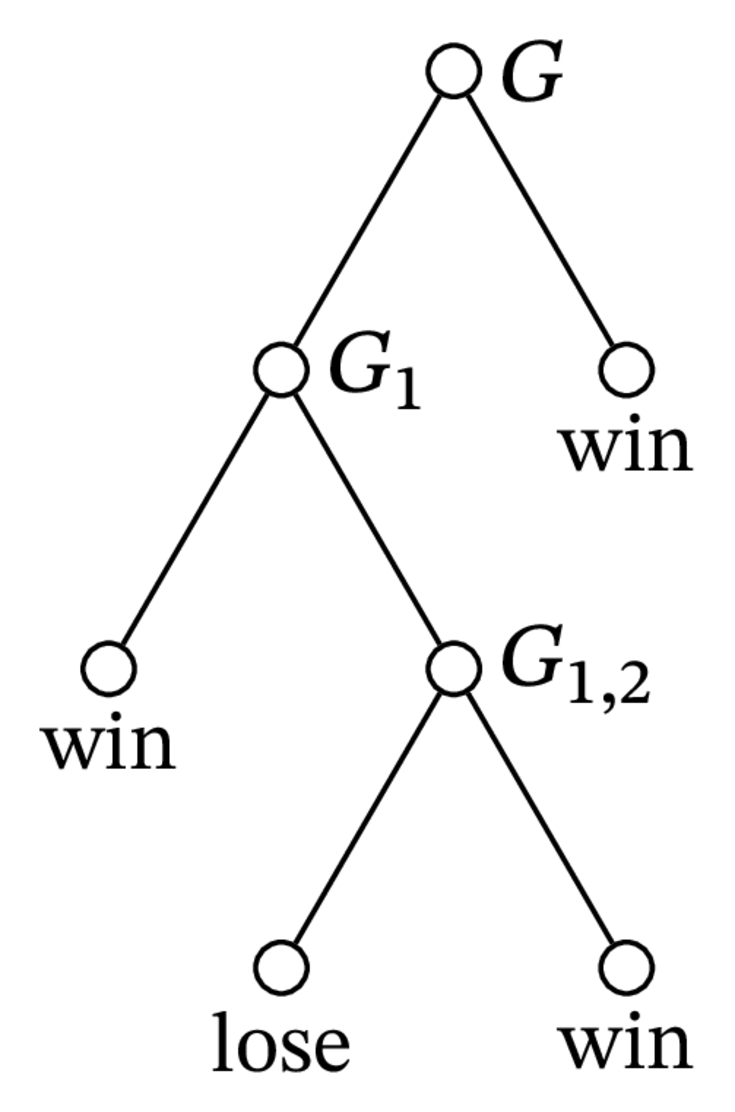
-
図 \(\text{7.7}\) に示す \(G\) を記号列として (山括弧、ラベル、\(\textbf{bintree}\), \(\textbf{leaf}\) などを使って) 表せ。
任意の \(G \in \text{binary-2PG}\) に対して、\(G\) の葉のラベルを「左」から「右」に並べた列を \(\text{flatten}(G)\) と定める。例えば図 \(\text{7.7}\) の \(G\) に対しては次の等式が成り立つ:
-
関数 \(\text{flatten}\) の再帰的定義を示せ。二つの列を連結する操作を使ってよい。
-
サイズと \(\text{flatten}\) の定義に関する構造的帰納法で次の等式を示せ:
\[ 2 \cdot \text{length}(\text{flatten}(G)) = |G| + 1 \tag{7.50}\]
問題 7.7
文字列をその反転 (reversal) に対応付ける関数 \(\operatorname{rev}\colon A^{\ast} \to A^{\ast}\) には、次に示す単純な再帰的定義が存在する:
-
ベースケース: \(\operatorname{rev}(\lambda) ::= \lambda\)
-
構築ケース: 任意の \(s \in A^{\ast}\) と \(a \in A\) に対して \(\operatorname{rev}(as) ::= \operatorname{rev}(s) a\)
文字列 \(s\) が \(\operatorname{rev}(s) = s\) を満たすとき、\(s\) を回文 (palindrome) と呼ぶ。回文全体の集合にも次に示す単純な再帰的定義が存在する。この定義は定義する集合を \(\text{RecPal}\) と表している:
-
ベースケース: \(\lambda \in \text{RecPal}\) および任意の \(a \in A\) に対して \(a \in \text{RecPal}\)
-
構築ケース: \(s \in \text{RecPal}\) なら任意の \(a \in A\) に対して \(asa \in \text{RecPal}\)
この再帰的定義が本当に回文全体の集合に等しいことの証明は構造的帰納法の良い練習になる。解答では、文字列の連結と反転に関する次の三つの性質を仮定してよい:
任意の \(r, s, t \in A^{\ast}\) で次の関係が成り立つ:
(等式 \(\text{(7.52)}\) と等式 \(\text{(7.53)}\) はそれぞれ問題 7.2 と問題 7.3 で個別に示した。)
-
全ての \(s \in \text{RecPal}\) で \(s = \operatorname{rev}(s)\) だと示せ。
-
逆に、文字列 \(s\) が \(s = \operatorname{rev}(s)\) を満たすなら \(s \in \text{RecPal}\) だと示せ。
ヒント: \(n = |s|\) に関する数学的帰納法を使う。
問題 7.8
\(m, n\) を \(0\) でない整数とする。整数の集合 \(L_{m, n}\) を次の規則で再帰的に定義する:
-
ベースケース: \(m, n \in L_{m, n}\)
-
構築ケース: \(j, k \in L_{m, n}\) のとき、\(-j \in L_{m, n}\) かつ \(j + k \in L_{m, n}\)
以降この問題では \(L_{m, n}\) を省略して \(L\) と表記する。
-
構造的帰納法を使って、\(m\) と \(n\) の公約数は \(L\) の任意の要素の約数でもあると示せ。
-
\(L\) の任意の要素の整数倍は \(L\) の要素だと示せ。
-
\(j, k \in L\) かつ \(k \neq 0\) なら \(\operatorname{rem}(j,k) \in L\) だと示せ。
-
\(L\) の任意の要素を割り切る正の整数 \(g \in L\) が存在することを示せ。
ヒント: \(L\) に含まれる最小の正整数である。
-
\(\text{(d)}\) の \(g\) が \(m\) と \(n\) の最大公約数 \(\operatorname{gcd}(m,n)\) だと結論付けよ。
問題 7.9
文字列 \(s \in A^{\ast}\) に含まれる \(c \in A\) の個数を表す \(\#_{c}(s)\) を、次の規則で文字列の定義に関して再帰的に定義する:
-
ベースケース: \(\#_{c}(\lambda) ::= 0\)
-
構築ケース: 任意の \(a \in A\) と \(s \in A^{\ast}\) に対して
\[ \#_{c}(\langle a,s \rangle) ::= \begin{cases} \#_{c}(s) & a \neq c \text{ のとき} \\ 1 + \#_{c}(s) & a = c \text{ のとき} \\ \end{cases} \]
構造的帰納法を使って、任意の \(s, t \in A^{\ast}\) と \(c \in A\) に対して次の等式が成り立つと示せ:
問題 7.10
フラクタル (fractal) は再帰的に定義される数学的オブジェクトの例である。この問題では Koch 雪片 (Koch snowflake) と呼ばれるフラクタルを考える。任意の Koch 雪片は次の再帰的定義で構築できる:
-
ベースケース: 一辺の長さが正の任意の正三角形は Koch 雪片である。
-
構築ケース: \(K\) を Koch 雪片、\(l\) を \(K\) を構成する任意の辺とする。\(l\) を三分割して中央の部分を取り除き、取り除いた辺を二つ使って橋渡しする (図 \(\text{7.8}\))。この操作の結果も Koch 雪片である。
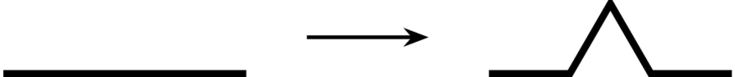
-
ちょうど \(9\) 個の辺を持ち、辺の長さが \(3\) 種類以上ある Koch 雪片を示せ。
-
構造的帰納法を使って、任意の Koch 雪片の内側の領域の面積が有理数 \(q\) を使って \(q \sqrt{3}\) と表せると示せ。帰納法の仮定、そして証明で必要になる仮定を明確に表明すること。
ヒント: Koch 雪片に関する事実を使うときは、それも構造的帰納法で証明する。
問題 7.11
赤黒木 (red-black tree) の集合 \(\text{RBT}\) は次の規則で再帰的に定義される:
-
ベースケース:
- \(\langle \textbf{red} \rangle \in \text{RBT}\)
- \(\langle \textbf{black} \rangle \in \text{RBT}\)
-
構築ケース: \(A, B \in RBT\) のとき
-
もし \(A\), \(B\) が \(\textbf{black}\) で始まるなら、\(\langle \textbf{red}, A, B \rangle \in \text{RBT}\)
-
もし \(A\), \(B\) が \(\textbf{red}\) で始まるなら、\(\langle \textbf{black}, A, B \rangle \in \text{RBT}\)
-
任意の \(T \in \text{RBT}\) に対して、\(r_{T}\), \(b_{T}\), \(n_{T}\) を次のように定める:
- \(r_{T} ::= T \text{ に含まれる } \textbf{red} \text{ の個数}\)
- \(b_{T} ::= T \text{ に含まれる } \textbf{black} \text{ の個数}\)
- \(n_{T} ::= r_{T} + b_{T} \quad (T \text{ に含まれるラベルの個数})\)
次の命題を示せ:
ヒント: \(\displaystyle \frac{n}{3} \leq r \ \ \longleftrightarrow \ \ \frac{2n}{3} \geq n - r \)
問題 7.12
一つの実数を引数に取る算術三角関数 (arithmetric trigonometric function) の集合 \(\text{Atirg}\) を次の規則で再帰的に定義する:
-
ベースケース:
-
恒等関数 \(\operatorname{id}(x) ::= x\) は \(\text{Atrig}\) に属する。
-
任意の定数関数は \(\text{Atrig}\) に属する。
-
サイン関数は \(\text{Atrig}\) に属する。
-
-
構築ケース: \(f, g \in \text{Atrig}\) のとき、次の関数も \(\text{Atrig}\) に属する:
- \(f + g\)
- \(f \cdot g\)
-
合成 \(f \circ g\)
構造的帰納法を使って、\(f \in \text{Atrig}\) なら \(f^{\prime} ::= df/dx\) も \(\text{Atrig}\) に属すると示せ。
問題 7.13
一つの実数を引数に取る有理関数 (rational function) の集合 \(\text{RAF}\) を次の規則で再帰的に定義する:
-
ベースケース:
-
恒等関数 \(\operatorname{id}(r) ::= r\) は \(\text{RAF}\) に属する。
-
任意の定数関数は \(\text{RAF}\) に属する
-
-
構築ケース: \(f, g \in \text{RAF}\) のとき、\(f \circledast g\) も \(\text{RAF}\) に属する。ここで \(\circledast\) は次に示す演算のいずれかである:
-
加算 \(+\)
-
乗算 \(\cdot\)
-
除算 \(/\)
-
-
次の条件を満たす関数 \(e, f, g \in \text{RAF}\) の構築方法を説明せよ:
\[ e \circ (f + g) \neq (e \circ f) + (e \circ g) \tag{7.55}\] -
任意の (\(\text{RAF}\) に属さないものを含む) 実数値関数 \(e, f, g\) に対して次の等式が成り立つと示せ:
\[ (e \circledast f) \circ g = (e \circ g) \circledast (f \circ g) \tag{7.56}\]ヒント: \((e \circledast f)(x) ::= e(x) \circledast f(x)\)
-
\(h \in \text{RAF}\) に関する述語 \(P(h)\) を次のように定める:
\[ P(h) \ \ \overset{\text{def}}{\longleftrightarrow}\ \ \forall g \in \text{RAF}.\ h \circ g \in \text{RAF} \]\(\text{RAF}\) の定義に関する構造的帰納法を使って、全ての \(h \in \text{RAF}\) で \(P(h)\) が成り立つと示せ。各ベースケースと各構築ケースをはっきりと表明すること。
問題 7.14
\(2\)-\(3\)-平均数 (\(2\)-\(3\)-averaged number) 全体の集合 \(\text{N23}\) は実数区間 \([0, 1]\) の部分集合であり、次の規則で再帰的に定義される:
-
ベースケース: \(0, 1 \in \text{N23}\)
-
構築ケース: \(a, b \in \text{N23}\) のとき、次の \(L(a, b)\) も \(\text{N23}\) に属する:
\[ L(a, b) ::= \frac{2a + 3b}{5} \]
-
通常の数学的帰納法または整列原理を使って、全ての非負整数 \(n\) で次の関係が成り立つと示せ:
\[ \left( \frac{3}{5} \right)^{\! n} \in \text{N23} \] -
構造的帰納法を使って、二つの \(2\)-\(3\)-平均数の積も \(2\)-\(3\)-平均数だと示せ。
ヒント: \(c \in \text{N23}\) に関する構造的帰納法で「もし \(d \in \text{N23}\) なら \(cd \in \text{N23}\)」を示す。
問題 7.15
この問題ではビット列 \(s \in \left\{ \texttt{0}, \texttt{1} \right\}^{\ast}\) を考える。
ビット列の集合の再帰的定義が cat-OK とは、構築ケースで要素が文字列の連結1として定義されることを言う。
例えば、\(\texttt{1}\) が一つだけ含まれるビット列全体の集合 \(\text{One1}\) の次の再帰的定義は cat-OK である:
-
ベースケース: 長さ \(1\) の文字列 \(\texttt{1}\) は \(\text{One1}\) に属する。
-
構築ケース: \(s \in \text{One1}\) なら \(\texttt{0}s\) と \(s\texttt{0}\) も \(\text{One1}\) に属する。
-
\(\texttt{0}\) だけからなる、長さが偶数のビット列全体の集合を \(E\) とする。\(E\) の cat-OK な再帰的定義を示せ。
-
文字列 \(s\) の反転 (reversal) を \(\operatorname{rev}(s)\) と表記する。例えば \(\operatorname{rev}(\texttt{001}) = \texttt{100}\) である。\(s = \operatorname{rev}(s)\) を満たす文字列 \(s\) を回文 (palindrome) と呼ぶ。例えば \(\texttt{11011}\) と \(\texttt{010010}\) は回文である。
回文であるビット列全体の集合の cat-OK な再帰的定義を示せ。
-
\(\texttt{0}\) だけからなる、長さが \(2\) の冪のビット列全体の集合を \(P\) とする。\(P\) の cat-OK な再帰的定義を示せ。
問題 7.16
集合 \(F_{1}\) と \(F_{2}\) を次の規則で再帰的に定義する:
-
\(F_{1}\):
- \(5 \in F_{1}\)
-
\(n \in F_{1}\) のとき \(5n \in F_{1}\)
-
\(F_{2}\):
- \(5 \in F_{2}\)
-
\(n, m \in F_{1}\) のとき \(nm \in F_{2}\)
-
これら二つの定義の一方が曖昧だと示せ。再帰的定義が「曖昧」とは数学的な定義が特定の性質を持つことを意味するのであって、定義の意味が一意に定まらず定義に失敗していることを意味しない点に注意せよ。
-
曖昧な定義と比べたとき、曖昧でない定義が持つ利点を簡単に説明せよ。
-
\(F_{1} = F_{2}\) を証明するアプローチの一つに、\(F_{1} \subseteq F_{2}\) と \(F_{2} \subseteq F_{1}\) を個別に示す方法がある。二つの包含関係の一方は構造的帰納法で簡単に証明できる。それはどちらか? 帰納法の仮定は何か? 証明を完成させる必要はない。
問題 7.17
括弧からなるバランスの取れた文字列全体の集合 \(\text{RecMatch}\) の再帰的定義は定義 7.2.1 で与えた。また、同じ集合を \(\text{AmbRecMatch}\) として定義する曖昧な再帰的定義は定義 7.2.4 で与えた。
設問の誘導に従って、次の命題の証明を完成させよ:
(実際には \(\text{RecMatch} = \text{AmbRecMatch}\) である。これは問題 7.20 で証明する。)
-
構造的帰納法で \((\ast)\) を証明するとき、使うことになる帰納法の仮定を書け。
-
証明のベースケースを書け。
-
証明の構築ケースを書け。
\(\text{RecMatch}\) の利点として、定義が曖昧でないことがある。\(\text{AmbRecMatch}\) の定義は曖昧である。
-
\(\text{AmbRecMatch}\) に属することが二つの異なる方法で示せる文字列の例を示せ。
-
曖昧な定義と比べたとき、曖昧でない定義が持つ利点を簡単に説明せよ。再帰的定義が「曖昧」とは数学的な定義が特定の性質を持つことを意味するのであって、定義の意味が一意に定まらず定義に失敗していることを意味しない点に注意せよ。
問題 7.18
括弧からなるバランスの取れた文字全体の集合を定義 7.2.1 の通り \(\text{RecMatch}\) とする。\(\text{RecMatch}\) が文字列の結合に関して閉じていることを証明せよ。言い換えれば、もし \(s, t \in \text{RecMatch}\) なら \(s \cdot t \in \text{RecMatch}\) だと示せ。
問題 7.19
\(p\) を文字列 \({\color{red} \,\textbf{\textsf{[}}\,}{\color{blue} \,\textbf{\textsf{]}}\,}\) とする。括弧からなる文字列 \(s\) が削除可能 (erasable) とは、\(s\) から \(p\) を繰り返し削除することで空文字列にできることを言う。例として次の文字列を考える:
この文字列からは三つの \(p\) を削除できる。実際に削除すると、文字列が得られる:
この文字列から一つの \(p\) を削除すると、次の文字列となる:
これは \(p\) そのものなので、\(p\) を削除すれば空文字列 \(\lambda\) となる。よって最初の文字列 \({\color{red} \,\textbf{\textsf{[}}\,}{\color{red} \,\textbf{\textsf{[}}\,}{\color{red} \,\textbf{\textsf{[}}\,}{\color{blue} \,\textbf{\textsf{]}}\,}{\color{blue} \,\textbf{\textsf{]}}\,}{\color{red} \,\textbf{\textsf{[}}\,}{\color{blue} \,\textbf{\textsf{]}}\,}{\color{blue} \,\textbf{\textsf{]}}\,}{\color{red} \,\textbf{\textsf{[}}\,}{\color{blue} \,\textbf{\textsf{]}}\,}\) は削除可能と分かる。
一方で、文字列
は削除可能でない。実際、\(p\) の削除を進めると途中で詰まってしまう。文字列 \(\text{(7.57)}\) から二つの \(p\) を削除すると次の文字列が得られる:
さらに一つの \(p\) を削除すれば、次の文字列となる:
この文字列は \(p\) を含まないので、\(p\) の削除を続けることはできない2。
括弧からなる削除可能な文字列全体の集合を \(\text{Erasable}\) とする。括弧からなるバランスの取れた文字列全体の集合を定義 7.2.1 の通り \(\text{RecMatch}\) とする。
-
構造的帰納法で次の包含関係を示せ:
\[ \text{RecMatch} \subseteq \text{Erasable} \] -
逆向きの包含関係
\[ \text{Erasable} \subseteq \text{RecMatch} \]の証明を次に示す。\((\ast)\) で示された設問に答えよ。
証明 文字列の長さ \(n\) に関する強い数学的帰納法を使って、\(\text{Erasable}\) に属する文字列は \(\text{RecMatch}\) にも属すると示す。次の述語 \(P(n)\) を帰納法の仮定とする:
ベースケース: \((\ast)\) ベースケースを説明し、そのとき \(P(n)\) が正しいと証明せよ。
帰納ステップ: \(n\) を非負整数として、\(n\) 以下の非負整数で \(P(n)\) が正しいと仮定する。さらに \(P(n+1)\) を示すために、\(x \in \text{Erasable}\) かつ \(|x| = n + 1\) だとも仮定する。この上で \(x \in \text{RecMatch}\) を示せばよい。
文字列 \(z\) に含まれる \(p\) を一つだけ削除して得られる文字列が \(y\) のとき、\(y\) を \(z\) の削除結果 (erase) と呼ぶことにする。
\(x \in \text{Erasable}\) かつ \(|x| = n + 1 > 0\) より、\(x\) の削除結果 \(y \in \text{Erasable}\) が存在する。\(|y| = n - 1 \leq n\) かつ \(y \in \text{Erasable}\) なので、帰納法の仮定より \(y \in \text{RecMatch}\) が分かる。
以降の議論は二つの場合に分かれる:
-
\(y\) が空文字列のとき、\((\ast)\) \(x \in \text{RecMatch}\) だと示せ。
-
\(s, t \in \text{RecMatch}\) を使って \(y = {\color{red} \,\textbf{\textsf{[}}\,} s {\color{blue} \,\textbf{\textsf{]}}\,} t\) と表せるとき、さらに場合を分けて考える:
-
\(x = py\) のとき、\((\ast)\) \(x \in \text{RecMatch}\) だと示せ。
-
削除結果が \(s\) である文字列 \(s^{\prime}\) を使って \(x = {\color{red} \,\textbf{\textsf{[}}\,} s^{\prime} {\color{blue} \,\textbf{\textsf{]}}\,} t\) と表せるとき、\((a)\) の結果と \(s \in \text{RecMatch}\) より \(s\) は削除可能である。これは \(s^{\prime}\) が削除可能であることも意味する。一方 \(| s^{\prime} | < |x|\) なので、帰納法の仮定より \(s^{\prime} \in \text{RecMatch}\) が分かる。よって \(x\) は \(\text{RecMatch}\) の定義における構築ケースの条件を満たすので、\(x \in \text{RecMatch}\) を得る。
-
削除結果が \(t\) である文字列 \(t^{\prime}\) を使って \(x = {\color{red} \,\textbf{\textsf{[}}\,} s {\color{blue} \,\textbf{\textsf{]}}\,} t^{\prime}\) と表せるとき、\((\ast)\) \(x \in \text{RecMatch}\) だと示せ。
-
\((\ast)\) これらの場合を考えれば十分な理由を説明せよ。
以上で強い数学的帰納法による証明が完了した。よって \(P(n)\) は全ての非負整数 \(n\) で成り立つ。言い換えれば任意の \(x \in \text{Rrasable}\) は \(x \in \text{RecMatch}\) を満たす。つまり \(\text{Erasable} \subseteq \text{RecMatch}\) である。 ■
\(\text{(a)}\), \(\text{(b)}\) の結果より
を得る。
問題 7.20
この問題では定義 7.2.1 の \(\text{RecMatch}\) と定義 7.2.4 の \(\text{AmbRecMatch}\) が同一の集合だと示す。
-
\(\text{RecMatch}\) が文字列の連結に関して閉じていると示せ。言い換えれば、任意の \(s, t \in \text{RecMatch}\) に対して \(s \cdot t \in \text{RecMatch}\) だと示せ。
-
構造的帰納法で \(\text{AmbRecMatch} \subseteq \text{RecMatch}\) を示せ。
-
\(\text{RecMatch} = \text{AmbRecMatch}\) を示せ。
問題 7.21
括弧からなる文字列のバランスが取れている (つまり \(\text{RecMatch}\) に属する) かどうかを判定する方法の一つとして、カウンターを \(0\) で初期化してから文字列を一文字ずつ左から右に読み、開き括弧を読むたびにカウンターを \(1\) 増やし、閉じ括弧を読むたびにカウンターを \(1\) 減らす手続きを使う方法がある。この手続きを二つの文字列に対して実行したときのカウンターの値の変化を次に示す:
この手続き全体でカウンターの値が負にならず、かつ最後の値が \(0\) のとき、文字列は優れたカウント (good count) を持つと言うことにする。上に示した二つ目の文字列は優れたカウントを持つのに対して、一つ目の文字列はカウンターの値が負になる箇所があるので優れたカウントを持たない。次のように集合 \(\text{GoodCount}\) を定める:
空文字列は優れたカウントを持つと定める。つまり \(\lambda \in \text{GoodCount}\) とする。括弧のバランスの取れた文字列が優れたカウントを持つ文字列にちょうど等しいことを示そう。
-
\(\text{RecMatch}\) の定義に関する構造的帰納法で \(\text{GoodCount}\) が \(\text{RecMatch}\) を含むことを示せ。
-
逆に、\(\text{RecMatch}\) が \(\text{GoodCount}\) を含むことを示せ。
ヒント: \(\text{GoodCount}\) に含まれる文字列の長さに関する数学的帰納法を使う。カウンターの値が二度目に \(0\) になる位置に注目する。
問題 7.22
問題 5.10 と同様に、正三角形分割 (divided equilateral triangle, DET) は次のように定義される:
-
単一の正三角形は DET である。
-
\(T\) が DET のとき、\(4\) 個の \(T\) を図 \(\text{7.9}\) のように並べた正三角形 \(T^{\prime}\) も DET である。
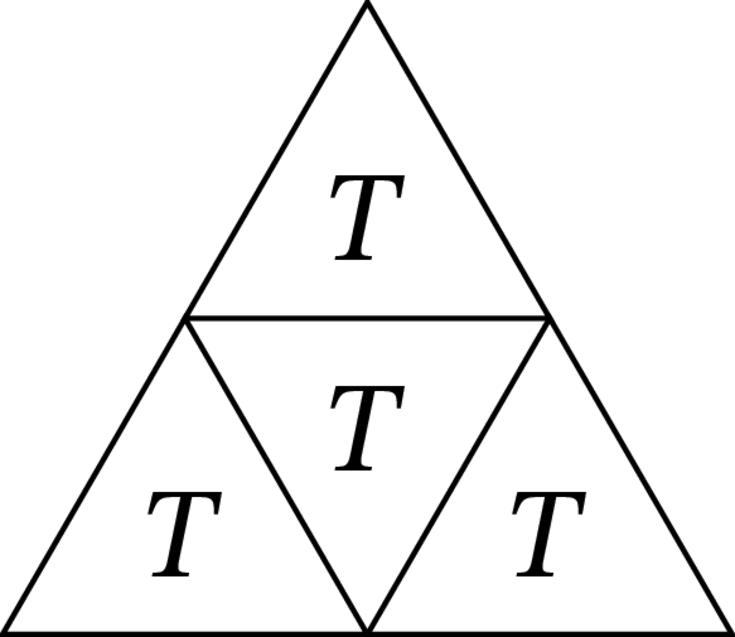
問題 5.10 では DET の性質を数学的帰納法で証明した。DET の定義が再帰的であることを利用すれば、構造的帰納法で DET の性質を証明できる。
-
DET から隅にある単位正三角形を \(1\) 個取り除いた図形には、\(3\) 個の単位正三角形からなる台形 (図 \(\text{7.11}\)) を敷き詰められることを構造的帰納法で示せ。
-
DET から特定の一辺の中央にある単位三角形を取り除いた図形には、\(3\) 個の単位正三角形からなる台形 (図 \(\text{7.11}\)) を敷き詰められると示せ。図 \(\text{7.10}\) に示すように、一辺に偶数個の単位正三角形が並んでいるとき「中央の単位正三角形」は二つある。
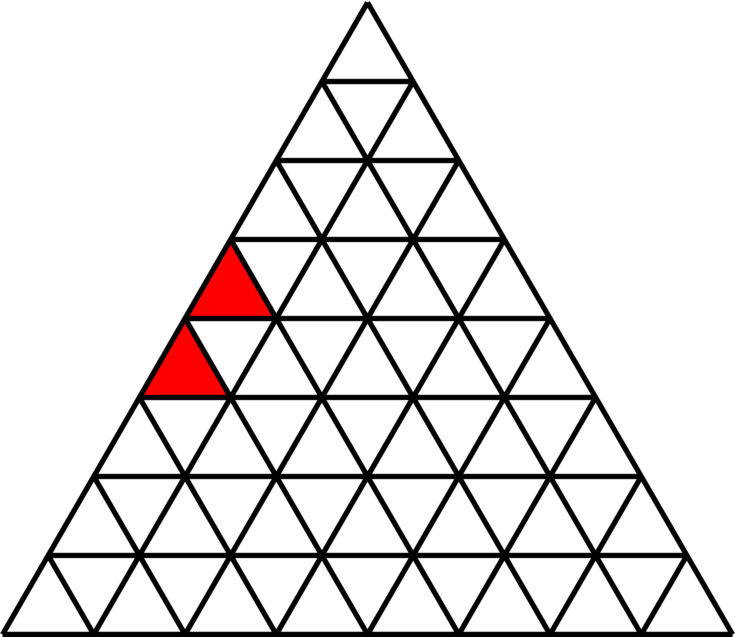
-
第 5.1.5 項で触れた L 字タイルを中庭に敷き詰める問題では、大きな正方形から任意の単位正方形を一つ取り除いた領域に L 字タイルを敷き詰める方法があることを証明した。\(\text{(b)}\) の結果からすると、DET に関しても同じことが言えるのではないだろうか? しかし、その予想は正しくない:
誤った主張DET から任意の単位正三角形を一つ取り除いた領域に上記の台形を敷き詰める方法が存在する。
\(\text{(a)}\) と同様の構造的帰納法を使った、この誤った主張の誤った証明を次に示す:
誤った証明 DET が一つの単位正三角形からなるとき、主張は明らかに成り立つ。
続いて \(T^{\prime}\) が四つの正三角形 \(T\) から構成される場合を考える。四つの \(T\) は同一なので、単位正三角形がどこから取り除かれたと考えても構わない。そこで上部の正三角形 \(T_{0}\) から単位正三角形が取り除かれたと仮定する。このとき帰納法の仮定から、\(T_{0}\) に台形を敷き詰める方法が存在する。他の三つの \(T\) については、\(\text{(a)}\) の結果と第 5.1.5 項と同様の議論より台形を敷き詰められると分かる。以上で \(T^{\prime}\) から任意の単位正三角形を一つ取り除いた領域に台形を敷き詰める方法が示せた。
よって構造的帰納法の原理より、\(T^{\prime}\) から任意の単位正三角形を一つ取り除いた領域に台形を敷き詰める方法が存在する。 ■
この証明の誤りは何か?
ヒント: 反例を見つけ、どこで議論が破綻するか調べる。
(取り除いたとき台形の敷き詰めが可能になる単位正三角形の位置の単純な特徴付けを著者たちは知らない。)
問題 7.23
\(\texttt{0}\) と \(\texttt{1}\) が並んだ有限列を二進単語 (binary word) と呼ぶ。この問題では二進単語を単に「単語」と呼ぶ。例えば \((\texttt{1}, \texttt{1}, \texttt{0})\) と \((\texttt{1})\) は単語であり、それぞれ \(3\) と \(1\) の長さを持つ。単語を表記するときは括弧とコンマを省略することが多い。例えば上記の単語は \(\texttt{110}\) および \(\texttt{1}\) と表記される。
単語の後に別の単語を連結する基礎的な操作を連結 (concatenation) と呼ぶ。例えば \(\texttt{101}\) と \(\texttt{1}\) を連結すると \(\texttt{1101}\) になる。また、\(\texttt{110}\) をそれ自身と連結した結果は \(\texttt{110110}\) である。
二つの単語に対する連結操作は、二つの単語の集合に対する操作に拡張できる。単語と単語の集合の違いを強調するため、これからは単語の集合を言語 (language) と呼ぶ。\(R\) と \(S\) が言語のとき、それらの連結 \(R \cdot S\) は \(R\) に属する単語と \(S\) に属する単語の連結全体の集合と定義される。つまり、次のように定義される:
例えば、次の等式が成り立つ:
\(D \cdot D\) は \(D^{2}\) と略記される。例えば \(D ::= \left\{ \texttt{1}, \texttt{0} \right\}\) のとき、\(D^{2}\) は次の言語となる:
言い換えれば、\(D^{2}\) は \(D\) に含まれる \(2\) 個の単語を連結して得られる列全体の集合である。一般に、\(D\) に含まれる \(n\) 個の単語を連結して得られる列全体の集合を \(D^{n}\) と表記する。
\(S\) が言語のとき、\(S\) に属する単語をいくつか連結して得られる単語全体の集合を \(S^{\ast}\) と表記する (「エス・スター」と読む)。慣習により、\(S^{\ast}\) は空単語 \(\lambda\) を常に含む。例えば、\(\left\{ \texttt{0}, \texttt{11} \right\}^{\ast}\) は \(\texttt{0}\) と \(\texttt{11}\) を並べて作成できる単語全体の言語である。この言語は「\(1\) が必ず偶数個連続して並ぶ文字列全体の言語」とも言い換えられる。また、\((D^{2})^{\ast}\) は長さが偶数の単語全体の言語を表す。最後に、単語全体の集合 \(D^{\ast}\) を \(B\) と定める。
連結定義可能 (concatenation-definable) な言語全体の集合 \(\text{C-D}\) を次の規則で再帰的に定義する:
-
ベースケース: 任意の有限言語は \(\text{C-D}\) に属する
-
構築ケース: \(L\) と \(M\) が \(\text{C-D}\) に属するとき、次の三つの言語も \(\text{C-D}\) に属する:
\[ L \cdot M, \qquad L \cup M, \qquad \overline{\mathstrut L} \]
この定義が \({}^{\ast}\) を含まない点に注意してほしい。このため、連結定義可能な言語をスター自由言語 (star-free language) と呼ぶこともある [36]。
様々な興味深い言語が連結定義可能である一方で、非常に単純であるにもかかわらず連結定義可能でない言語も存在する。この問題では \(\left\{ \texttt{00} \right\}^{\ast}\) (\(\texttt{0}\) が偶数個並んだ単語全体の言語) が連結定義可能でないことを示す。
-
単語全体の集合 \(B\) が連結定義可能だと示せ。
ヒント: 空集合は有限集合である。
連結定義可能な言語のさらに興味深い例として、連続する \(3\) 個の \(\texttt{1}\) を同じ単語が挟む形をした全ての単語からなる言語がある。つまり、この言語に属する単語は次の形をしている:
なお、上記の記号列を正確に表記すれば \(B \cdot \left\{ \texttt{111} \right\} \cdot B\) であるものの、可読性のため省略しても曖昧さが生まれないドットと単元集合に対する波括弧を省略している。この略記は以降でも使われる。
-
\(\texttt{0}\) で始まって \(1\) で終わる単語全体の言語が連結定義可能だと示せ。
-
\(0^{\ast}\) が連結定義可能だと示せ。
-
\(R\) と \(S\) が連結定義可能なら、\(R \cap S\) も連結定義可能だと示せ。
-
\(\left\{ 01 \right\}^{\ast}\) が連結定義可能だと示せ。
言語 \(S\) が \(\texttt{0}\) だけからなる単語を有限個しか含まないとき、つまり \(S\, \cap\,\texttt{0}^{\ast}\) が有限集合のとき、\(S\) を \(0\)-有限 (\(0\)-finite) と呼ぶことにする。また、\(S\) と \(\overline{\mathstrut S}\) の少なくとも一方が \(0\)-有限のとき、\(S\) を \(0\)-退屈 (\(0\)-boring) と呼ぶ。以降では \(0\)-退屈を単に「退屈」と表記する。
-
\(\left\{ \texttt{00} \right\}^{\ast}\) が退屈でない理由を説明せよ。
-
\(R\) と \(S\) が退屈なら \(R \cup S\) も退屈だと確認せよ。
-
\(R\) と \(S\) が退屈なら \(R \cdot S\) も退屈だと確認せよ。
ヒント: 場合分けを用いる: \(R\) と \(S\) が両方とも \(0\)-有限のとき、\(R\) と \(S\) のいずれかが \(0\) だけからなる単語 (空単語 \(\lambda\) を含む) を一つも持たないとき、それ以外のときを考える。
-
構造的帰納法を使って、全ての連結定義可能な言語は退屈だと結論付けよ。
以上の結果から、\(0\) だけからなる偶数長の単語全体の言語 \((\texttt{00})^{\ast}\) は連結定義可能でないと分かる。
問題 7.24
デジタル回路を再帰的データ型 \(\text{DigCirc}\) として定義すると、デジタル回路の動作を簡潔かつ正確に記述できるようになり、構造的帰納法という強力な証明技法を使った性質の検証が可能になる。全てのゲートが \(2\) 入力だと定義が簡単になるので、この問題では \(1\) 入力の \(\operatorname{\text{\footnotesize NOT}}\) の代わりに \(2\) 入力の \(\operatorname{\text{\footnotesize NOR}}\) を基本ゲートとして用いる。基本ゲートの集合 \(\text{Gates}\) を次のように定める:
このとき、デジタル回路は \((x, y, G, I)\) の形をしたゲート接続 (gate connection) の並んだリストとして再帰的に定義される。ここで \(G\) はゲート、\(x\) と \(y\) は \(G\) の入力ワイヤ、そして \(I\) はゲートの出力ワイヤが接続される箇所を表す (図 \(\text{7.12}\))。
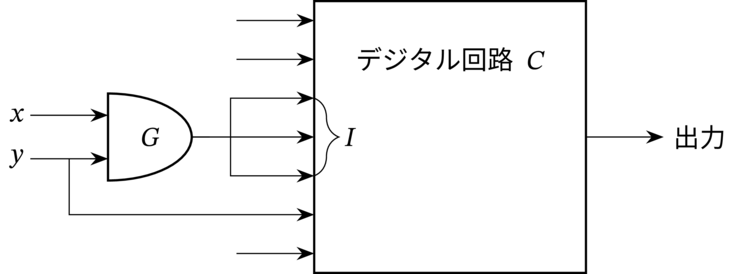
形式的には次の通りである。\(W = \left\{ w_{0}, w_{1}, \ldots \right\}\) をワイヤ (wire) 全体の集合、\(\textbf{O} \notin W\) を出力 (output) と呼ばれるオブジェクトとする。
デジタル回路全体の集合 \(\text{DigCirc}\) と、デジタル回路 \(C\) の入力ワイヤ \(\operatorname{inputs}(C)\) と内部ワイヤ \(\operatorname{internal}(C)\) は次の規則で再帰的に定義される:
-
ベースケース: 任意の \(x, y \in W\) と \(G \in \text{Gates}\) に対して、次の \(C\) は \(\text{DigCirc}\) に属する:
\[ C = \operatorname{list} ((x, y, G, \left\{ \textbf{O} \right\})) \quad (\text{一要素のリスト})\\ \]この \(C\) に対する \(\operatorname{inputs}(C)\) と \(\operatorname{internal}(C)\) は次のように定義される:
\[ \begin{aligned} \text{inputs}(C) &::= \left\{ x, y \right\} \\ \operatorname{internal}(C) &::= \left\{ \right\} \\ \end{aligned} \] -
構築ケース: 任意の
\[ \begin{aligned} C &\in \text{DigCirc} \\ G &\in \text{Gates} \\ I &\subseteq \text{inputs}(C),\ I \neq \varnothing \\ x, y &\in W - (I \cup \operatorname{internal}(C)) \end{aligned} \]に対して、次の \(D\) は \(\text{DigCirc}\) に属する:
\[ D = \operatorname{cons}( (x, y, G, I), C) \\ \]この \(D\) に対する \(\operatorname{inputs}(D)\) と \(\operatorname{internal}(D)\) は次のように定義される:
\[ \begin{aligned} \text{inputs}(D) &::= \left\{ x, y \right\} \cup (\text{inputs}(C) - I) \\ \operatorname{internal}(D) &::= \operatorname{internal}(C) \cup I \end{aligned} \]
任意のデジタル回路 \(C\) に対して、関数 \(\text{wires}\) を次のように定める:
\(C\) のワイヤ割り当て (wire assignment) とは次の関数 \(\alpha\) を意味する:
ただし、任意の \((x, y, G, I) \in C\) に対して次の関係が成り立つとする:
-
デジタル回路 \(C\) に対する二つのワイヤ割り当てが \(\operatorname{inputs}(C)\) に対して同じ値を割り当てるなら、他の全てのワイヤに対しても同じ値を割り当てると示せ。
デジタル回路 \(C\) に対する環境 (environment) とは関数 \(e\colon \operatorname{inputs}(C) \to \left\{ \textbf{T}, \textbf{F} \right\}\) を言う。\(\text{(a)}\) の結果からは、デジタル回路 \(C\) の任意の環境 \(e\) に対して、次の関係を満たすワイヤ割り当て \(\alpha_{e}\) が一つだけ存在すると分かる:
よって任意の環境 \(e\) に対して、デジタル回路は出力 \(\textbf{O}\) の値を一意に定める。つまり次の関数 \(\operatorname{eval}\colon \text{DigCirc} \times \operatorname{inputs}(C) \to \left\{ \textbf{T}, \textbf{F} \right\}\) が存在する:
何らかのデジタル回路 \(C\) の入力ワイヤを命題変数に持つ命題論理式 \(F\) を考える。全ての環境 \(e\) で次の関係が成り立つとき、\(C\) と \(F\) は同値 (equivalent) であると言う:
-
デジタル回路を同値な命題論理式に変換する関数 \(E\) を、デジタル回路の定義に関して再帰的に定義せよ。
-
命題論理式 \(E(C)\) がデジタル回路 \(C\) より指数的に大きくなる \(C\) の例を見つけよ。
問題 7.25
\(P\) を命題変数とする。
-
命題変数 \(P\) と定数 \(\textbf{T}\) と論理結合子 \(\operatorname{\text{\footnotesize XOR}}\), \(\operatorname{\text{\footnotesize AND}}\) だけを使って \(\operatorname{\text{\footnotesize NOT}} (P)\) を表現せよ。
定数 \(\textbf{T}\) の使用は \(\text{(a)}\) で不可欠である。これを証明するため、\(\operatorname{\text{\footnotesize XOR}}\) と \(\operatorname{\text{\footnotesize AND}}\) だけからなる (\(\textbf{T}\) を使わない) 命題論理式の集合 \(\text{PXA}\) を次の規則で再帰的に定義する:
-
ベースケース: 命題論理式 \(P\) は \(\text{PXA}\) に属する。
-
構築ケース: \(R, S \in \text{PXA}\) のとき、命題論理式 \(\,R \ \operatorname{\text{\footnotesize XOR}}\ S\,\) と \(\,R \ \operatorname{\text{\footnotesize AND}} \ S\,\) も \(\text{PXA}\) に属する。
例えば、次の命題論理式は \(\text{PXA}\) に属する:
-
\(\text{PXA}\) の定義に関する構造的帰納法を使って、\(\text{PXA}\) に属する任意の命題論理式は \(P\) または \(\textbf{F}\) と同値だと示せ。
問題 7.26
Ackermann 関数 (Ackermann function) のとあるバージョン \(A\colon \mathbb{N}^{2} \to \mathbb{N}\) は次の規則で再帰的に定義される:
\(B\colon \mathbb{N}^{2} \to \mathbb{N}\) が上記の規則を満たす部分関数であるとき、\(B\) は全域で \(B = A\) だと示せ。
問題 7.27
-
第 7.4.1 項で説明した環境モデルと置換モデルのそれぞれについて、次の式の評価がどのように進行するかステップごとに示せ:
\[ \operatorname{eval}(\operatorname{subst}(3x, x(x - 1)), 2) \]各ステップで適用される規則を \(\operatorname{eval}\) の定義 (7.4.2) と \(\operatorname{subst}\) の定義 (7.4.3) にある式番号で明示すること。必要になる算術演算と変数参照の回数を二つのモデル間で比較せよ。
-
環境モデルを使うと置換モデルを使う場合より評価で必要な乗算が \(6\) 回少ないような \(\text{(a)}\) と同様の形をした式を答えよ。評価の各ステップを示す必要はない。
-
置換モデルを使うと環境モデルを使う場合より評価で必要な乗算が \(6\) 回少ないような \(\text{(a)}\) と同様の形をした式を答えよ。評価の各ステップを示す必要はない。
問題 7.28
この問題では、真理値に対して作用する論理演算と、命題論理式で演算を表す記号の区別を通常以上に意識する必要がある。演算を表す記号として \(\textbf{And}\), \(\textbf{Not}\) (それぞれ論理演算 \(\operatorname{\text{\footnotesize AND}}\), \(\operatorname{\text{\footnotesize NOT}}\) に対応する) だけが含まれる命題論理式だけを考える。また、定数を表す記号 \(\textbf{T}\), \(\textbf{F}\) も命題論理式で使ってよいと定める。
-
命題論理式 \(F\) と、命題論理式 \(F\) に現れる命題変数全体の集合を返す関数 \(\operatorname{pvar}(F)\) の単純な再帰的定義を書け。
\(V\) を命題変数の集合とする。\(V\) 上の真理環境 (truth environment) とは、\(V\) に含まれる全ての変数に対する真理値の割り当てを言う。言い換えれば、次の全域関数 \(e\) が \(V\) 上の真理環境である:
-
\(F\) を命題論理式、\(e\) を \(\text{pvar(F)} \subseteq V\) であるような \(V\) 上の真理環境とする。\(e\) における \(F\) の真理値 \(\operatorname{eval}(F, e)\) の再帰的定義を示せ。
明らかに、命題論理式の真理値は命題変数に割り当てられる値にのみ依存する。それ以外の何に依存できるだろうか? しかし、この事実の厳密な証明は良い練習になる。
-
命題変数 \(P\) を含むにもかかわらず真理値が \(P\) に依存しない命題論理式の例を示せ。また、「命題論理式 \(F\) の真理値が命題論理式 \(P\) に依存しない」の厳密な定義を示せ。
ヒント: \(e_{1}\), \(e_{2}\) を \(P\) 以外の全ての命題変数に対する真理値が一致する真理環境とする。
-
「命題論理式の真理値は、それに含まれる命題変数の真理値だけに依存する」の厳密な定義を示し、それを命題論理式の定義に関する構造的帰納法で証明せよ。
-
同じ要領で命題論理式の恒真性 (validity) も厳密に定義できる。命題論理式 \(F\) が恒真なのは次の関係が成り立つとき、かつそのときに限る:
\[ \forall e.\ \operatorname{eval}(F, e) = \textbf{T} \]同様の方法で命題論理式 \(G\) の充足不能性 (unsatisfiability) を厳密に定義せよ。その定義と \(\operatorname{eval}\) の定義を使って、命題論理式 \(F\) が恒真なのは \(\textbf{Not}(F)\) が充足不能なとき、かつそのときに限ると示せ。
問題 7.29
MVAO (mutivariable \(\text{AND-OR}\), 多変数 \(\text{AND-OR}\)) と呼ばれる命題論理式は次の規則で再帰的に定義される:
-
ベースケース: 単一の命題変数および定数 \(\textbf{True}\), \(\textbf{False}\) は \(\text{MVAO}\) である。
-
構築ケース: \(G, H\) が \(\text{MVAO}\) のとき、\(G \ \operatorname{\text{\footnotesize AND}} \ H\) と \(G \ \operatorname{\text{\footnotesize OR}}\ H\) も \(\text{MVAO}\) である。
MVAO な命題論理式の例を次に示す:
命題論理式 \(G\) が \(\textbf{False}\)-減少 (\(\textbf{False}\)-decreasing) とは、\(G\) で使われている命題変数を \(\textbf{False}\) で置き換えると \(G\) が「より \(\textbf{False}\)」になることを言う。正確に言えば、\(G\) で命題変数が使われている部分のいくつかを \(\textbf{False}\) で置き換えた結果を \(G^{f}\) とするとき、\(G\) を偽にする任意の真理値割り当てが \(G^{f}\) も偽にするなら、\(G\) は \(\textbf{False}\)-減少である。
例えば、単一の命題変数 \(P\) だけから構成される命題論理式は \(\textbf{False}\)-減少である: これは \(P^{f} = \textbf{False}\) から分かる。一方、\(G ::= \overline{\mathstrut P}\) は \(\text{False}\)-減少でない: \(G^{f} = \overline{\mathstrut \textbf{False}}\) であり、これは \(G\) の真にする (任意の) 真理値割り当てで真になる。
構造的帰納法を使って、MVAO な全ての命題論理式が \(\textbf{False}\)-減少だと示せ。
問題 7.30
この問題では定義 7.2.1 で定めた集合 \(\text{RecMatch}\) と、定義 7.4.1 で定めた集合 \(\text{Aexp}\) が利用される。
-
\(e \in \text{Aexp}\) に含まれる括弧以外の記号を全て除去する関数 \(\operatorname{erase}(e)\) の再帰的定義を示せ。例えば次の等式が成り立つ:
\[ \operatorname{erase}({\color{red} \,\textbf{\textsf{[}}\,}{\color{red} \,\textbf{\textsf{[}}\,} 3 \times {\color{red} \,\textbf{\textsf{[}}\,} x \times x {\color{blue} \,\textbf{\textsf{]}}\,} {\color{blue} \,\textbf{\textsf{]}}\,} + {\color{red} \,\textbf{\textsf{[}}\,} {\color{red} \,\textbf{\textsf{[}}\,} 2 \times x {\color{blue} \,\textbf{\textsf{]}}\,} + 1 {\color{blue} \,\textbf{\textsf{]}}\,} {\color{blue} \,\textbf{\textsf{]}}\,}) = {\color{red} \,\textbf{\textsf{[}}\,}{\color{red} \,\textbf{\textsf{[}}\,} {\color{red} \,\textbf{\textsf{[}}\,} {\color{blue} \,\textbf{\textsf{]}}\,} {\color{blue} \,\textbf{\textsf{]}}\,} {\color{red} \,\textbf{\textsf{[}}\,} {\color{red} \,\textbf{\textsf{[}}\,} {\color{blue} \,\textbf{\textsf{]}}\,} {\color{blue} \,\textbf{\textsf{]}}\,} {\color{blue} \,\textbf{\textsf{]}}\,} \] -
全ての \(e \in \text{Aexp}\) で \(\operatorname{erase}(e) \in \text{RecMatch}\) だと示せ。
-
任意の \(e \in \text{Aexp}\) に対して \({\color{red} \,\textbf{\textsf{[}}\,} s {\color{blue} \,\textbf{\textsf{]}}\,} \neq \operatorname{erase}(e)\) となる短い文字列 \(s \in \text{RecMatch}\) の例を示せ。
問題 7.31
述語論理式を再帰的データ型として定義すると、自由変数や冠頭形といった述語論理式に関する概念・性質を再帰的定義で簡単に定義できる。
この問題では論理結合子として \(\textbf{And}\), \(\textbf{Not}\), \(\textbf{Implies}\) だけを考える ── これらの扱い方を示せば他の論理結合子の扱い方も分かる。簡単のため、原子論理式は変数に適用された述語だけとする。つまり、この問題では関数記号と等号 \(=\) が現れない述語論理式を考える。
-
ベースケース: 述語記号 \(P\) と変数記号 \(u, \ldots, v\) に対して、\(P(u, \ldots, v)\) は述語論理式である。\(u, \ldots, v\) が全て異なる必要はない。
-
構築ケース: \(F\) と \(G\) が述語論理式なら、次に示す記号列も述語論理式である:
\[ \textbf{Not}(F), \quad (F\ \ \textbf{And}\ \ G), \quad (F\ \ \textbf{Implies}\ \ G), \quad (\exists x.\ F), \quad (\forall x.\ F) \]ここで \(x\) は変数を表す。
-
述語論理式 \(F\) の自由変数 (free variable) 全体の集合を返す関数 \(\operatorname{fvar}(F)\) の再帰的定義を示せ。\(F\) で変数 \(x\) が自由とは、\(F\) の \(\exists x.\ [\cdots]\) または \(\forall x.\ [\cdots]\) の内部でない箇所で \(x\) が出現することを言う。
述語論理式が冠頭形 (prenex form) とは、全ての量化子が先頭にあることを言う。いくつかの例を問題 3.42 で示した。形式的に定義すると、冠頭形の述語論理式は次の形をしている:
ここで \(\operatorname{bod}(F)\) は量化子を持たない述語論理式を表す。\(\operatorname{qnt}(F)\) は量化子の (空の可能性もある) 列を表し、次の形をしている:
ただし各 \(Q_{i}\) は \(\forall\) または \(\exists\) であり、各 \(x_{i}\) は異なる変数である。
述語論理式 \(F\) を同値な冠頭形の述語論理式に変換する処理は、\(F\) が一意変数規則 (unique variable convention) を満たすとき簡単になる: 述語論理式 \(F\) が一意変数規則を満たすとは、\(F\) に含まれる任意の変数 \(x\) に対して、\(x\) が自由変数として使われるなら \(\exists x\) と \(\forall x\) が \(F\) に含まれず、\(x\) が自由変数として使われないなら \(\exists x\) と \(\forall x\) の一方だけが一度だけ \(F\) に含まれることを言う。(変数の改名を通して述語論理式を一意変数規則が満たされるように変形する手続きは問題 3.41 で考えた。一般的な手続きは問題 7.32 で見る。)
-
一意変数規則を満たす述語論理式を \(F\) とする。\(F\) を同値な冠頭形の述語論理式であって本体が \(F\) から量化子を除去した記号列に等しいものに変換する手続きを、述語論理式の定義に関して再帰的に定義せよ。(つまり \(F\) に含まれる論理結合子は変化しない。そのため、これは問題 3.42 で示した方法とは異なる。)
次の形をした量化子の列を表す \(\overline{\mathstrut \operatorname{qnt}(F)}\) を定義すると便利だろう:
\[ \overline{\mathstrut Q_{1}}x_{1}\ \overline{\mathstrut Q_{2}}x_{2},\ \ldots,\ \overline{\mathstrut Q_{n}}x_{n} \]ここで \(\overline{\mathstrut \forall} ::= \exists\) および \(\overline{\mathstrut \exists} ::= \forall\) と定める。
例えば \(Q x.\ F\) が部分式のとき、一意変数規則から他の部分で \(x\) が使われないことが保証される。よって次の関係が分かる:
\[ (Q x.\ F)\ \ \textbf{And}\ \ G\quad \longleftrightarrow \quad Q x.\ (F\ \ \textbf{And}\ \ G) \]なぜなら \(G\) を単なる \(\textbf{True}\) または \(\textbf{False}\) とみなせるからである。同じ理由で、次の \(\operatorname{qnt}(F\ \ \textbf{And}\ \ G)\) と \(\operatorname{bod}(F\ \ \textbf{And}\ \ G)\) の定義は同値性を保存する:
\[ \begin{aligned} \operatorname{bod}(F\ \ \textbf{And}\ \ G) &::= (\operatorname{bod}(F)\ \ \textbf{And}\ \ \operatorname{bod}(G)) \\ \operatorname{qnt}(F\ \ \textbf{And}\ \ G) &::= \operatorname{qnt}(F)\ \operatorname{qnt}(G) \end{aligned} \]
問題 7.32
モダンなプログラミング言語では、異なる手続きで同名の手続きやパラメータを使っても問題は起こらない。特定の文脈で特定の名前が参照する手続きやパラメータは、プログラミング言語の「スコープ規則 (scoping rule)」によって曖昧さなく決定される。プログラマーは自由に名前を選択でき、手続きはその名前が一意であり他の個所で使われないかのように振る舞う。
同じ性質は述語論理式でも考えることができる3。一つの述語論理式に同じ記号を束縛する量化子 \(\forall x\), \(\exists x\) が両方あるとき、それぞれの本体で記号 \(x\) は異なる意味で使われる。しかし、変数の名前を変更すれば述語論理式の意味や構造を変えずに変数束縛の曖昧性を除去できる。この手続きの例は問題 3.41 で見た。
この問題では、述語論理式に含まれる命題変数の名前を変更する関数 \(\operatorname{UV}\) の再帰的定義を考える。\(\operatorname{UV}\) は任意の述語論理式 \(F\) を受け取り、次の一意変数規則 (unique variable convention) を満たす \(F\) と同値な述語論理式 \(\operatorname{UV}(F)\) を返す:
-
\(\operatorname{UV}(F)\) に含まれる任意の変数 \(x\) について、量化された \(x\) の使用は \(1\) 回以下である。つまり、\(\forall x\) と \(\exists x\) のどちらかを一回だけ使うことが許される。
-
\(\operatorname{UV}(F)\) が \(\forall x.\ G\) または \(\exists x.\ G\) の形をした部分式を持つとき、\(F\) 全体で \(x\) は \(G\) の中でのみ使用される。
ここからは論理結合子を表す記号と論理演算を区別しない。例えば、記号 \(\textbf{And}\) と演算 \(\operatorname{\text{\footnotesize AND}}\) を同一視する。また、述語論理式に含まれる論理結合子は \(\operatorname{\text{\footnotesize AND}}\) と \(\operatorname{\text{\footnotesize NOT}}\) だけとする。
関数 \(\operatorname{UV}\) を定義するには、自由変数と束縛変数の両方の名前を記号的に変更する操作が必要になる。そこで、\(F\) に含まれる \(x\) を記号的に \(y\) へ変更する関数 \(\operatorname{renm}(F, x := y)\) を定義する:
名前の変更関数 \(\operatorname{renm}\) は次の規則で再帰的に定義される:
-
ベースケース: 変数 \(x\), \(y\), \(z\) に対して:
\[ \begin{aligned} \operatorname{renm}(x, x := y) &::= y \\ \operatorname{renm}(z, x := y) &::= z \qquad (x \text{ と } z \text{ は異なる変数とする})\\ \end{aligned} \] -
ベースケース: 述語 \(P(u, \ldots, v)\) に対して:
\[ \operatorname{renm}(P(u, \ldots, v), x := y) ::= P(\operatorname{renm}(u, x:= y), \ldots, \operatorname{renm}(v, x:= y)) \] -
構築ケース: 述語論理式 \(G\), \(H\) と変数 \(u\), \(v\), \(x\), \(y\) に対して:
\[ \begin{aligned} \operatorname{renm}(\operatorname{\text{\footnotesize NOT}} (G), x := y) &::= \operatorname{\text{\footnotesize NOT}} (\operatorname{renm}(G, x := y)) \\ \operatorname{renm}((G \ \operatorname{\text{\footnotesize AND}} \ H) , x := y) &::= (\operatorname{renm}(G, x := y) \ \operatorname{\text{\footnotesize AND}} \ \operatorname{renm}(H, x := y)) \\ \operatorname{renm}(\forall u.\ G, x := y) &::= \forall \operatorname{renm}(u, x := y).\ \operatorname{renm}(G, x := y) \\ \operatorname{renm}(\exists u.\ G, x := y) &::= \exists \operatorname{renm}(u, x := y).\ \operatorname{renm}(G, x := y) \end{aligned} \]
一意変数規則を満たすように述語論理式を変形する関数 \(\operatorname{UV}\) を定義するには、二つの引数を取る補助関数 \(\operatorname{UV}_{2}\) の定義が必要になる。\(\operatorname{UV}_{2}\) は変換される述語論理式 \(F\) と、使用済みの (そのため使用してはいけない) 変数の集合 \(V\) を引数に取る。さらに、\(\operatorname{UV}_{2}(F, V)\) は組を返す: \(\operatorname{left}(\operatorname{UV}_{2}(F, V))\) は一意変数規則を満たす変換後の述語論理式、\(\operatorname{right}(\operatorname{UV}_{2}(F, V))\) は \(\operatorname{left}(\operatorname{UV}_{2}(F, V))\) で使用される変数全体の集合である。この集合に含まれる変数は、他の部分の変換で使用してはいけない。この上で、\(\operatorname{UV}\) は次のように定義される:
\(\text{UV}_{2}\) の定義を次に示す。有限集合 \(V\) に属さない「新しい」変数を返す関数 \(\operatorname{newvar}(V)\) が利用可能だと仮定している:
-
ベースケース: \(F = P(u, \ldots ,v)\) のとき:
\[ \begin{aligned} \operatorname{left}(\operatorname{UV}_{2}(F, V)) &::= F \\ \operatorname{right}(\operatorname{UV}_{2}(F, V)) &::= V \cup \left\{ u, \ldots, v \right\} \end{aligned} \] -
構築ケース:
-
\(F = \operatorname{\text{\footnotesize NOT}} (G)\) のとき:
\[ \begin{aligned} \operatorname{left}(\operatorname{UV}_{2}(F, V)) &::= \operatorname{\text{\footnotesize NOT}} (\operatorname{left}(\operatorname{UV}_{2}(G, V))) \\ \operatorname{right}(\operatorname{UV}_{2}(F, V)) &::= \operatorname{right}(\operatorname{UV}_{2}(G, V)) \end{aligned} \] -
\(F = (G \ \operatorname{\text{\footnotesize AND}} \ H)\) のとき、\(V^{\prime} ::= \operatorname{right}(\operatorname{UV}_{2}(G, V))\) とした上で:
\[ \begin{aligned} \operatorname{left}(\operatorname{UV}_{2}(F, V)) &::= (\operatorname{left}(\operatorname{UV}_{2}(G, V)) \ \operatorname{\text{\footnotesize AND}} \ \operatorname{left}(\operatorname{UV}_{2}(H, V^{\prime}))) \\ \operatorname{right}(\operatorname{UV}_{2}(F, V)) &::= \operatorname{right}(\operatorname{UV}_{2}(H, V^{\prime})) \end{aligned} \] -
\(F = Q x.\ G \ \ (Q \in \left\{ \forall, \exists \right\})\) のとき、\(y ::= \operatorname{newvar}(V)\), \(V^{\prime} ::= V \cup \left\{ y \right\}\) とした上で:
\[ \begin{aligned} \operatorname{left}(\operatorname{UV}_{2}(F, V)) &::= Q y.\ \operatorname{renm}((\operatorname{left}(\operatorname{UV}_{2}(G, V^{\prime}))), x := y) \\ \operatorname{right}(\operatorname{UV}_{2}(F, V)) &::= \operatorname{right}(\operatorname{UV}_{2}(G, V^{\prime})) \end{aligned} \]
-
-
任意の述語論理式には自由変数という集合が定義される。同値な述語論理式への変換の前後で自由変数は変わらないはずである。任意の述語論理式 \(F\) と変数の集合 \(V\) に対して次の等式が成り立つと示せ:
\[ \operatorname{fvar}(F) = \operatorname{fvar}(\operatorname{UV}_{2}(F,V)) \] -
\(\operatorname{left}(\operatorname{UV}_{2}(F, V))\) で \(V\) に含まれる変数が使用されないと示せ。
-
\(\operatorname{left}(\operatorname{UV}_{2}(F, V))\) が一意変数規則を満たすと示せ。
-
避けるべき変数の集合が設定されない \(\operatorname{UV}\) 関数は述語論理式を標準形に変換することを示せ。つまり、任意の述語論理式 \(F\) と変数の集合 \(V\) で次の等式が成り立つと示せ:
\[ \operatorname{UV}(\operatorname{UV}_{2}(F, V)) = \operatorname{UV}(F) \]
問題 7.33
通常の 〇×ゲーム (Tic-Tac-Toe) において、先攻プレイヤーが最初に × を書く位置には \(9\) 通りの選択肢があり、後攻プレイヤーが最初に 〇 を書く場所には \(8\) 通りの選択肢がある。よって最初の二手が終わった後の盤面には \(72\) 通りの可能性がある。
-
先攻プレイヤーが二つ目の × を書いた後の盤面は何通り存在するか?
-
この単純な方法で盤面の可能性を正確に計算できなくなる最初の盤面は何手目か?
問題 7.34
-
\(4\) 個の石が積まれた山が \(1\) 個ある状態から始まるニムの最初の操作の結果として生じるニムのゲーム全体からなる集合 \(\text{Fmv}{\langle 4 \rangle}\) を示せ。
-
\(\text{Nim}_{\langle 4 \rangle}\) を純粋集合 (「一番下」に空集合だけが存在する集合) として表せ。
-
\(\left\{ \left\{ \left\{ \left\{ \varnothing \right\} \right\} \right\} \right\}\) が表すのはどんなニムのゲームか?
問題 7.35
この問題では広範なゲームの表す再帰的データ型 \(\text{VG}\) を定義し、構造的帰納法でゲーム戦略の基礎定理を示す。\(\text{VG}\) が表すのはゲームが終了したとき各プレイヤーに数値のスコアが計算される二人完全情報ゲームである。チェスやチェッカーのように勝敗しか決まるだけのゲームでも、\(1\), \(-1\), \(0\) がそれぞれ勝利、敗北、引き分けを表すと考えられるので、第 7.5 節で考えた勝敗確定二人完全情報ゲームは全て \(\text{VG}\) として表せる。また、囲碁は確保した石の数を表す「目」と呼ばれるスコアを計算してから勝敗が決まるので、\(\text{VG}\) として表現した方がある意味で自然となる。
形式的な定義は次の通りである:
\(V\) を実数の非空集合とする。\(V\) 上の \(V\)-値二人確定完全情報ゲーム (\(V\)-valued two-person deterministic games of perfect information) を表すクラス \(VG\) は、次の規則で再帰的に定義される:
-
ベースケース: 全ての \(v \in V\) は \(\text{VG}\) に含まれる。これらの要素を結果 (payoff) と呼ぶ。
-
\(G\) が VG の要素の非空集合のとき、\(G\) は \(VG\) に含まれる。\(M \in G\) を \(G\) の初期操作 (first move) と呼ぶ。
プレイヤーが持つ戦略 (strategy) とは、自分の番に何をすべきかを決定する規則を言う。さらに正確に言えば、\(s\) が戦略とは、\(s\) がゲームを受け取ってゲームを返す関数であって、全てのゲーム \(G\) で \(s(G) \in G\) が成り立つことを意味する。二人のプレイヤーに対する戦略が与えられれば二人が実行する操作が完全に決定するので、どちらが先攻かを決めればゲームの結果が一意に定まる4。
ゲームを遊ぶ二人のうち、一人は最大の結果が保証される戦略を望む \(\text{max}\) プレイヤー で、もう一人は最小の結果が保証される戦略を望む \(\text{min}\) プレイヤーだと仮定する。
\(\text{VG}\) の基礎定理は、この仮定があるとき任意のゲームで両方のプレイヤーに最適な戦略が存在し、それらの戦略は同じ結果を保証すると示す:
\(V\) を実数の有限集合、\(G\) を \(V\) が値域の \(\text{VG}\) とする。\(\text{max}\) プレイヤーが先攻なら、次の条件を満たす \(\text{max}_{G} \in V\) が存在する:
-
\(\text{max}\) プレイヤーには、相手の \(\text{min}\) プレイヤーがどんな戦略を用いたとしても \(\text{max}_{G}\) 以上の結果が保証される戦略が存在する。
-
\(\text{min}\) プレイヤーには、相手の \(\text{max}\) プレイヤーがどんな戦略を用いたとしても \(\text{max}_{G}\) 以下の結果が保証される戦略が存在する。
\(\text{max}_{G}\) の定義から「\(G\) に対する \(\text{max}_{G}\) が存在するなら、それは一意」だと分かる事実は強調に値する。つまり、最適な戦略を知っている二人が対戦するとき \(\text{max}\) プレイヤーが先攻ならゲームをプレイする意味はない: ゲームは必ず結果 \(\text{max}_{G}\) で終了する。
-
\(\text{VG}\) の基礎定理を証明せよ。
ヒント: \(\text{VG}\) は再帰的に定義されるデータ型なので、\(\text{VG}\) の任意の要素が何らかの性質を持つことを示すための標準的な手法は \(\text{VG}\) の定義に関する構造的帰納法である。先攻の \(\text{max}\) プレイヤーが初期操作を選択するとき、後攻の \(\text{min}\) プレイヤーは相手が選択したゲームに応じた初期操作を選択することに注意せよ。帰納法の仮定はこの事実を考慮する必要がある。
-
[スキップ可] 可能な結果全体の集合 \(V\) が無限集合である場合に対する基礎定理の自然な一般化を表明せよ。
問題 7.36
ニム (Nim) は石がいくつか積まれた山がいくつかある状態から始まる二人用ゲームである。各プレイヤーは一つの山から一つ以上の石を取り除く操作を交互に実行し、最後の石を取ったプレイヤーが勝利する。
ニムには片方のプレイヤーに必勝戦略が存在する。これは簡単に実行できるものの、見つけるのは少し難しい。
この必勝戦略を説明するために、非負整数の二つの表現に注目する: それを表すアラビア数字と、その二進表記を表すビット列である (先頭に \(\texttt{0}\) が付いても構わないとする)。
非負整数 \(r\), \(s\), \(\ldots\) の \(\operatorname{\text{\footnotesize XOR}}\) はビット列による表現を使って定義できる: \(r\), \(s\), \(\ldots\) のビット列による表現を \(\operatorname{\text{\footnotesize XOR}}\) で組み合わせ、その結果を二進表記として読んだときの非負整数と定めればよい。例えば、次の等式が成り立つ:
この計算を表す模式図を次に示す。各列の先頭から三行の値を \(\operatorname{\text{\footnotesize XOR}}\) した結果が一番下の行に並んでいる:
なお、\(\operatorname{\text{\footnotesize XOR}}\) の計算は繰り上がりを無視する二進数の加算と同じである (参照: 問題 3.6)。
ニムのゲームにおいて、それぞれの山にある石の個数の \(\operatorname{\text{\footnotesize XOR}}\) をニム和 (Nim sum) と呼ぶ。この問題では、いずれかのプレイヤーのターン開始時にニム和が \(0\) でないなら、そのプレイヤーに必勝戦略が存在することを示す。例えば、同じ高さの山が \(5\) 個ある状態から始まるニムのゲームでは、先攻のプレイヤーに必勝戦略が存在する。一方で、最初に同じ高さの山が \(4\) 個あるときは後攻のプレイヤーに必勝戦略がある。
-
ニム和が \(0\) のとき、任意の操作はニム和を \(0\) でない値に変更すると示せ。
-
ある山 \(S\) が条件「\(S\) 以外の山のニム和より多くの石が \(S\) に積まれている」を満たすなら、ニム和を \(0\) にする操作が存在すると示せ。
-
ニム和が \(0\) でないなら、ある山 \(S\) で条件「\(S\) 以外の山のニム和より多くの石が \(S\) に積まれている」が満たされると示せ。
ヒント: 「ある山 \(S\)」が最も多くの石が積まれた山とは限らないことに注意する。例えば、三つの山に積まれた石の個数がそれぞれ \(2\), \(2\), \(1\) なら、\(1\) 個の石が積まれた山が条件を満たす \(S\) となる。
-
ニム和が \(0\) でない状態からゲームが始まるとき、先攻のプレイヤーに必勝戦略が存在することを示せ。
ヒント: 先攻のプレイヤーが成立させられる保存不変条件を見つける。
-
[ボーナス点] ニムは勝者と敗者が逆転したルールで遊ばれることもある: つまり、最後の石を取ったプレイヤーの敗北となる。ここまでの結果を参考にしながら、この「貧乏クジ」バージョンのニムにおける必勝戦略を見つけよ。
問題 7.37
全ての木 \(T \in \text{RecTr}\) (定義 7.6.8) が数値のラベル \(\operatorname{num}(T) \in \mathbb{R}\) を持つとする。\(T\) の最小値 (minimum value) \(\operatorname{min}(T)\) とは、\(T\) の部分木が持つラベルの中で最も小さい値を意味する。関数 \(\text{recmin}\colon \text{RecTr} \to \mathbb{R}\) を次の規則で再帰的に定義する:
-
ベースケース: \(T \in \text{Leaves}\) のとき:
\[ \text{recmin}(T) ::= \operatorname{num}(T) \] -
構築ケース: \(T \in \text{Branching}\) のとき:
\[ \text{recmin}(T) ::= \operatorname{min} \left\{ \operatorname{num}(T),\ \text{recmin}(\operatorname{left}(T)),\ \text{recmin}(\operatorname{right}(T)) \right\} \]
全ての \(T \in \text{RecTr}\) で次の等式が成り立つと示せ:
問題 7.39
任意の \(T \in \text{BBTr}\) に対して、次のように \(\operatorname{leaves}(T)\) と \(\operatorname{internal}(T)\) を定義する:
-
\(T \in \text{Branching}\) のとき、次の等式が定義から直ちに従う理由を説明せよ:
\[ \begin{aligned} \operatorname{leaves}(T) &= \operatorname{leaves}(\operatorname{left}(T)) \cup \operatorname{leaves}(\operatorname{right}(T)) \\ \operatorname{internal}(T) &= \left\{ T \right\} \cup \operatorname{internal}(\operatorname{left}(T)) \cup \operatorname{internal}(\operatorname{right}(T)) \end{aligned} \] -
\(\text{RecTr}\) の定義 (7.6.8) に関する構造的帰納法を使って、任意の再帰木の「内部」部分木は葉より \(1\) 個だけ多いことを示せ。つまり、次の補題を示せ:
補題任意の \(T \in \text{RecTr}\) で次の等式が成り立つ:
\[ | \operatorname{leaves}(T) | = 1 + | \operatorname{internal}(T) | \]
問題 7.40
図 \(\text{7.13}\) に示すように、\(B\) を深さ \(d\) の AVL 木、\(S\) を深さ \(d + 2\) の AVL 木、\(N\) を \(B\) と \(S\) を直下の部分木に持つ探索木とする。さらに、図の通り \(S\) の直下の部分木は深さ \(d + 1\) の AVL 木 \(R\) と深さ \(d\) の AVL 木 \(S\) とする。
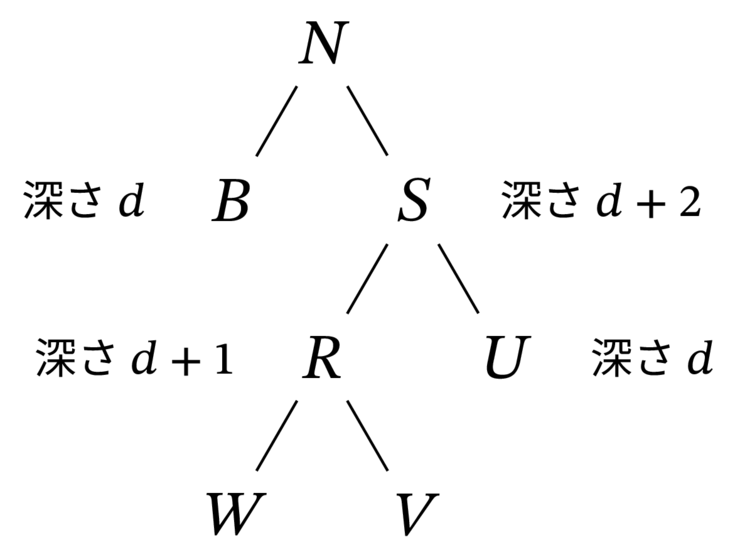
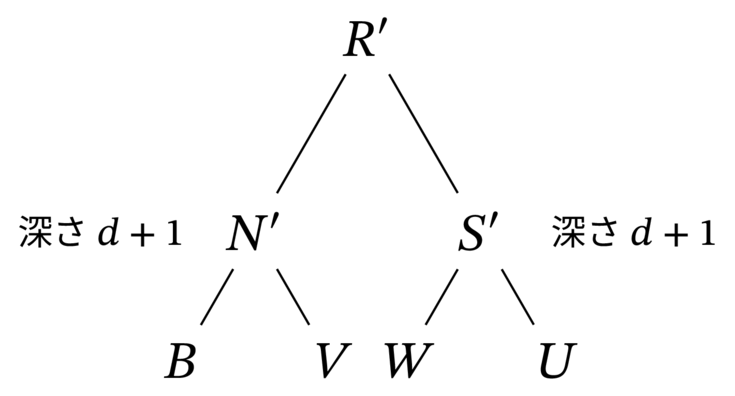
新しい木 \(R^{\prime}\), \(N^{\prime}\), \(S^{\prime}\) を次のように定義する。まず、ラベルは次のように定める:
そして、それぞれの直下の部分木は図 \(\text{7.14}\) の通りとする。
\(R^{\prime}\) が AVL 木であり、\(\text{nums}(R^{\prime}) = \text{nums}(N)\) が成り立つことを確かめよ。
問題 7.41
共有二分木 (sharing binary tree) 全体の集合 \(\text{SharTr}\) は次の規則で再帰的に定義される:
-
ベースケース: \(T \in \text{Leaves}\) のとき \(T\) は \(\text{SharTr}\) に属する。
-
構築ケース: \(T \in \text{Branching}\) のとき、もし \(\operatorname{left}(T), \operatorname{right}(T) \in \text{SharTr}\) なら \(T\) は \(\text{SharTr}\) に属する。
-
全ての \(T \in \text{SharTr}\) に対して \(\operatorname{size}(T)\) が有限だと示せ。
-
無限パスを持つ有限の \(T \in \text{BBTr}\) の例を示せ。
-
全ての \(T \in \text{BBTr}\) に対して次の関係が成り立つと示せ:
\[ T \in \text{SharTr}\ \ \longleftrightarrow\ \ T \text{ が無限パスを持たない} \] -
枝である部分木を三つ、葉である部分木を一つ持つ木 \(T_{3} \in \text{BBTr}\) の例を示せ。
-
次の補題を示せ:
補題任意の \(T \in \text{SharTr}\) で次の不等式が成り立つ:
\[ | \operatorname{leaves}(T) | \leq 1 + | \operatorname{internal}(T) | \]ヒント: 全ての \(T \in \text{SharTr}\) に対して、\(T\) と同じ個数の「内部」部分木と少なくとも \(T\) と同じ個数の葉を持つ再帰木 \(R \in \text{RecTr}\) が存在することを示す。
問題 7.42
-
次に示す木 \(T\) が探索木 (定義 7.6.24) となるように、それぞれの部分木のラベルに \(1\) から \(11\) までの整数を割り当てよ。
-
部分木のラベルが区間 \([a, b]\) に属する探索木 \(T\) とする。ただし \(a\), \(b\) は奇数で、\(b - a = \operatorname{size}(T) - 1\) と仮定する (例えば \([a,b] = [1, \text{size(T)}]\))。探索木の定義 (7.6.24) に関する構造的帰納法を使って、\(T\) の部分木が葉であるのはラベルが奇数のとき、かつそのときに限ると示せ。つまり、次の等式を証明せよ:
\[ \operatorname{leaves}(T) = \left\{ S \in \operatorname{Subtrs}(T) \; | \; \operatorname{num}(S) \text{ が奇数} \right\} \]ここから次のことが言える: ある値の集合が存在して、それに対する探索木と、そこから特定の値を一つ削除して特定の値を一つ追加した集合に対する探索木には共通する葉が一切存在せず、従って部分木も全て異なる。
例えば、\(n\) を奇数、\(T\) を \([1,n]\) に対する探索木とする。\(T\) から \(1\) を削除して \(n+1\) を追加した結果の探索木を \(U\) としたとき、\(U\) は \([2,n+1]\) に対する探索木である。\(T\) の葉は全て奇数のラベルを持つのに対して、\(U\) の葉は全て偶数のラベルを持つ (その理由5を考えよ!)。
これは AVL 木と対照的な結果と言える。AVL 木では全ての葉が二つの値を保持できるので、木全体の段階的な更新が可能になる。そのため値の挿入と削除において、操作前の木と操作後の木は異なる部分木を \(\log_{2} (\text{木のサイズ}) \) に比例する個数しか持たない。
問題 7.43
AVL 木から値を削除する手続き \(\operatorname{delete}(T, x)\) を定義し、その正しさを検証せよ。手続きが最悪の場合に実行するラベルの比較処理の実行回数、そして新しく導入する部分木の個数は AVL 木のサイズの対数に比例しなければならない。
問題 7.44
再帰木の定義 (7.6.8) に関する構造的帰納法を使って、全ての \(T \in \text{RecTr}\) で次の等式が成り立つと示せ:
問題 7.45
再帰木 \(T, U \in \text{RecTr}\) の同型 (isomorphism) 関係は次の規則で再帰的に定義される:
-
ベースケース: \(T \in \text{Leaves}\) のとき、\(T\) が \(U\) と同型なのは \(U \in \text{Leaves}\) のとき、かつそのときに限る。
-
構築ケース: \(T \in \text{Branching}\) のとき、\(T\) が \(U\) と同型なのは次の条件が全て成り立つとき、かつそのときに限る:
- \(U \in \text{Branching}\)
- \(\operatorname{left}(U) \text{ が } \operatorname{left}(T) \text{ と同型}\)
- \(\operatorname{right}(U) \text{ が } \operatorname{right}(T) \text{ と同型}\)
-
\(T \in \text{RecTr}\) と \(U \in \text{RecTr}\) が同型なら \(\operatorname{size}(T) = \operatorname{size}(U)\) だと示せ。
-
\(T\), \(U\) が同じ値の集合に対する探索木 ── つまり \(\text{nums}(T) = \text{nums}(U)\) ── で、同型だと仮定する。このとき \(\operatorname{num}(T) = \operatorname{num}(U)\) だと示せ。
ヒント: 同型と探索木の定義から示せる。構造的帰納法は必要ない。
問題 7.46
-
次に示す木 \(T\) が探索木 (定義 7.6.24) となるように、それぞれの部分木のラベルに \(1\) から \(15\) までの整数を割り当てよ。
-
任意の再帰木とラベルの集合が与えられたとき、その再帰木が探索木となるようにラベルを割り当てる方法は一つしか存在しない。より正確に言えば次の通りである: \(\operatorname{num}\colon \text{RecTr} \to \mathbb{R}\) が再帰木に対するラベル付け関数で、\(\operatorname{num}\) の下で \(T\) が探索木だと仮定する。\(\operatorname{num}\) と同じ値域を持つラベル付け関数 \(\operatorname{num}_{\text{alt}}\) が存在して、\(\operatorname{num}\) の下でも \(T\) は探索木になるとする。探索木の定義 (7.6.8) に関する構造的帰納法を使って、全ての部分木 \(S \in \operatorname{Subtrs}(T)\) で次の等式が成り立つと示せ:
\[ \operatorname{num}(S) = \operatorname{num}_{\text{alt}}(S) \tag{\text{same}} \]
-
二つの文字列 \(x\), \(y\) の連結 \(xy\) とは、\(x\) の終端に \(y\) をつなげることで得られる文字列を意味する。例えば \(\texttt{01}\) と \(\texttt{101}\) を連結した結果は \(\texttt{01101}\) である。 ↩︎
-
文字列から \(p\) を繰り返し削除するとき、\(p\) の選び方には複数の選択肢があることに注目してほしい。命題「\(p\) の削除を不可能になるまで繰り返し適用するとき、最終的に残る文字列はどのような順番で \(p\) を削除したとしても同じになる」は成り立つ。この事実をここでは証明せずに使っているものの、自明というわけでは決してない (問題 6.28 の結果を使うと示せる)。 ↩︎
-
歴史的には、変数束縛のスコープという問題は述語論理式の研究で最初に生まれた。 ↩︎
-
ここでは VG のゲームが無限に続かない事実を証明せずに用いている。この事実は勝敗確定ゲームに関する同様の補題 (7.5.2) と本質的に同一の構造的帰納法で示せる。 ↩︎
-
\(U\) の全てのラベルから \(1\) を引けば \([1,n]\) に対する探索木が得られる。また、\(\text{(b)}\) の議論は \(a\), \(b\) が偶数の場合にも適用できる。 ↩︎