\(E = \) [\(2^{26972607} - 1\) は素数]
18.4 樹形図で正しく確率を計算できる理由
目次
樹形図を使って確率の問題を解くことにも慣れてきた。ただ、樹形図を使う手法で正しく確率を計算できる理由は説明していない。その理由を一言で説明すれば「辺に割り当てられる確率が実際には条件付き確率だから」となる。
例えば、前節で示した樹形図 (図 \(\text{18.1}\)) の結果 \(WW\) に対応する一番上の路に注目してほしい。最初の辺に書かれた \(1/2\) は、チームが第一試合に勝つ確率を表す。そして二つ目の辺に書かれた \(2/3\) が表すのは、チームが第一試合に勝ったという条件の下でチームが第二試合に勝つ確率 ── 条件付き確率である! 一般的に言えば、樹形図の辺には「試行が親の頂点に到達したという条件の下で、試行がその辺に沿って進む確率」が記される。
つまり条件付き確率はこれまでにも利用していた。例えば、結果 \(WW\) の確率は次のように計算される:
\[ \operatorname{Pr} [WW] = \frac{1}{2} \cdot \frac{2}{3} = \frac{1}{3} \]
この計算が正しいのはどうしてだろうか?
この質問に答えるには、条件付き確率の定義 (定義 18.2.1) まで戻る必要がある。この定義から次の規則が分かる:
規則[条件付き確率の乗算則: (\(2\) 事象バージョン)]
\[ \operatorname{Pr} [E_{1} \cap E_{2}] = \operatorname{Pr}[E_{1}] \cdot \operatorname{Pr}[E_{2} \, | \, E_{1}] \]
樹形図の根から葉までの路に含まれる辺の確率を乗じると、この等式の右辺が得られる。例えば、次のような計算が起こる:
\[ \begin{aligned} & \operatorname{Pr} [ \text{第一試合に勝つ} \cap \text{第二試合に勝つ} ] \\ & \quad = \operatorname{Pr} [第一試合に勝つ] \cdot \operatorname{Pr} [\text{第二試合に勝つ} \, | \, \text{第一試合に勝つ}] \\[2pt] & \quad = \frac{1}{2} \cdot \frac{2}{3} \end{aligned} \]
つまり、樹形図の根から葉までの路に含まれる辺の確率の積を求めて結果の確率とする計算方法は条件付き確率の乗算則によって正当化される。
ただし、長さが \(3\) 以上の路に対する確率の計算を正当化するには、\(3\) 個の事象に対する乗算則が必要になる:
規則[条件付き確率の乗算則: (\(3\) 事象バージョン)]
\[ \operatorname{Pr} [E_{1} \cap E_{2} \cap E_{3}] = \operatorname{Pr} [E_{1}] \cdot \operatorname{Pr} [E_{2} \, | \, E_{1}] \cdot \operatorname{Pr} [E_{3} \, | \, E_{1} \cap E_{2}] \]
\(n\) 事象バージョンの乗算則は問題 18.1 に示してある。ただ、その式の形は \(3\) 事象バージョンから明らかだろう。
18.4.1 \(k\) 要素部分集合の確率
条件付き確率の乗算則の簡単な応用例として、\(1\) 以上 \(n\) 以下の整数全体の集合 \([1..n]\) の \(k\) 要素部分集合の個数を計算してみよう。もちろん、答えは \(\binom{n}{k}\) だと分かっている。ただ、条件付き確率の乗算則を使うと \(\binom{n}{k}\) を表す式の新しい導出が得られる。
\(k\) 要素部分集合 \(S \subseteq [1..n]\) を任意に取って固定する。\([1..n]\) の任意の \(k\) 要素部分集合に等しい確率を割り当てた上で、ランダムに選択した \(k\) 要素部分集合が \(S\) になる確率を \(p\) とする。このとき \(k\) 要素部分集合の個数は \(1/p\) である。
では \(p\) はどのように表せるだろうか? ランダムな \(k\) 要素部分集合の要素を一つずつ一様ランダムに決めていくとする。一つ目に選択される整数が \(S\) に属する確率は \(k/n\) である。さらに、一つ目に選択される整数が \(S\) に属するという条件の下で二つ目に選択される整数が \(S\) に属する確率は \((k - 1)/(n - 1)\) である。よって乗算則より、最初に選択される \(2\) 個の整数が両方とも \(S\) に属する確率は次に等しい:
\[ \frac{k}{n} \cdot \frac{k - 1}{n - 1} \]
さらに、最初に選択される二つの整数が両方とも \(S\) に属するという条件の下で、三つ目に選択される整数が \(S\) に属する確率は \((k - 2)/(n - 2)\) である。よって乗算則より、最初に選択される \(3\) 個の整数が全て \(S\) に属する確率は次に等しい:
\[ \frac{k}{n} \cdot \frac{k - 1}{n - 1} \cdot \frac{k - 2}{n - 2} \]
同様の議論を続ければ、選択される \(k\) 個の整数が全て \(S\) に含まれる確率、言い換えればランダムに選択した \(k\) 要素部分集合が \(S\) に等しい確率 \(p\) が次のように表せると分かる:
\[ \begin{aligned} p &= \frac{k}{n} \cdot \frac{k - 1}{n - 1} \cdot \frac{k - 2}{n - 2} \cdots \frac{k - (k - 1)}{n - (k - 1)} \\[10pt] &= \frac{k \cdot (k - 1) \cdot (k - 2) \cdots 1}{n \cdot (n - 1) \cdot (n - 2) \cdots (n - (k - 1))} \\[10pt] &= \frac{k!}{n!/(n-k)!} \\[10pt] &= \frac{k!(n - k)!}{n!} \end{aligned} \]
これで \([1..n]\) の \(k\) 要素部分集合の個数 \(1/p\) が求まった:
\[ \frac{n!}{k! (n - k)!} \]
18.4.2 医療検査
乳癌は毎年数千人の命を奪う致命的な疾患である。早期発見と正確な診断の重要性は非常に高く、定期的なマンモグラフィがその第一歩となる。ただ、マンモグラフィは絶対確実な医療検査というわけではなく、\(90\%\) から \(95\%\) 程度の正確性しか持たない1。人体への影響が少ない比較的安価な検査としては素晴らしい値と思うかもしれない。しかし、このマンモグラフィの結果もまた直感に反する事実が得られる条件付き確率の例である。正確性が \(90\%\) 以上のマンモグラフィであなた (またはあなたのパートナー) が陽性と判定されたら、あなたは乳癌の存在する確率が \(90\%\) 以上だと自然に考えるだろう。しかし、その自然な直感が誤っていることが数学的な解析から示せる。議論を進めるために、まずマンモグラフィの正確性を数学的に定義しておく:
-
患者が有病な (疾患を持つ) とき、検査は \(10\%\) の確率で「疾患を持たない」と判定する。これを偽陰性 (false negative) と呼ぶ。
-
患者が健康な (疾患を持たない) とき、検査は \(5\%\) の確率で「疾患を持つ」と判定する。これを偽陽性 (false positive) と呼ぶ。
18.4.3 またしても四ステップ法
患者は家族に癌の罹患歴がない中年の女性であり、この特徴を持つコホート (集団) における乳癌の有病率は \(1\%\) とする。
ステップ 1: 標本空間を見つける
標本空間は樹形図 \(\text{18.2}\) に示す通りである。\(P\) は陽性 (positive) の検査結果を、\(N\) は陰性 (negative) の検査結果を表す。
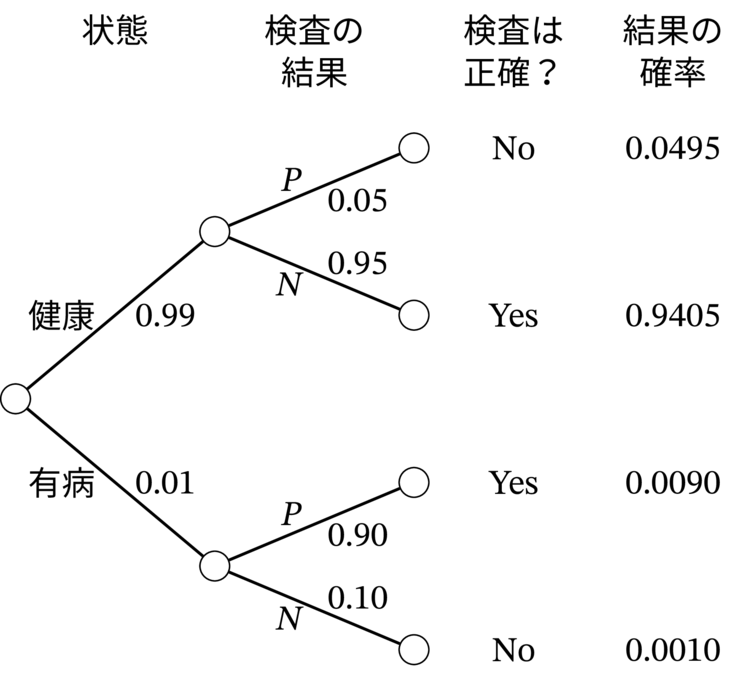
ステップ 2: 注目する事象を定義する
\(A\) を患者が有病である事象、\(B\) を検査結果が陽性となる事象とする。それぞれの事象に含まれる結果は樹形図から分かる。求めたいのは検査結果が陽性という条件の下で患者が有病な確率であり、この値は \(\operatorname{Pr}[ A \, | \, B]\) と表される。
ステップ 3: 結果の確率を計算する
まず辺に確率を割り当てる。この確率は問題の設定から直接得られる。乗算則より、根からの葉への任意の路に含まれる辺の確率の積は、その葉に対応する結果の確率に等しい。結果の確率は全て樹形図に書き込まれている。
ステップ 4: 事象の確率を求める
定義 18.2.1 から次のように求められる:
\[ \operatorname{Pr}[A \, | \, B] = \frac{\operatorname{Pr}[A \cap B]}{\operatorname{Pr}[B]} = \frac{0.009}{0.009 + 0.0495} \approx 15.4\% \]
つまり、この検査は約 \(95\%\) の正確性を持つにもかかわらず、陽性の検査結果が間違っている確率が約 \(84.6\%\) ある! 一見すると正確に思える検査も、決定的な情報を与えるわけではない。パーセントで表した正確性が検査の価値を正確に表さない事実は、\(99\%\) の「正確性」を持つ非常に簡単な検査方法が存在することからも分かる: 常に「健康です」と出力すればいい! この検査は \(99\%\) の健康患者に対しては常に正確となり、\(1\%\) の有病患者には常に不正確となる。しかし当然、現実の「正確性が劣る」検査の方がずっと価値がある。
18.4.4 実数を考える
検査結果が陽性である患者が実際に有病である確率が約 \(15\%\) という事実を知って驚いたかもしれない。しかし、次のように考えると納得できるだろう。陽性の検査結果が得られるシナリオは二つある: 一つは患者が有病で検査が正しいとき、もう一つは患者が健康で検査が間違っているときである。そして患者の大部分は乳癌に罹患していない! 健康な患者があまりにも多いので、わずか \(5\%\) の偽陽性の件数が実際に有病な患者の人数を上回ってしまう。
条件付き確率が関係する奇妙な結論を目にしたときは、このように「実数」を考えると納得できる場合が多い。マンモグラフィの例を使った例を示す。
\(10{,}000\) 人の女性が検査を受けたとする。乳癌の有病率は \(1\%\) なので、この中の \(100\) 人が乳癌を患っていると推定できる。有病患者に対する検査の正確性は \(90\%\) なので、この中で陽性の検査結果が出るのは \(90\) 人である。一方、健康患者に対する検査の正確性は \(95\%\) なので、乳癌を患っていない残りの \(9{,}900\) 人の中で \(495\) 人には偽陽性の結果が出る。つまり、検査結果が陽性になる患者は合わせて \(600\) 人弱いる。こう考えれば、陽性の検査結果の \(85\%\) が誤りという事実も意外ではないだろう。
18.4.5 事後確率
この医療検査の問題について深く考えると、確率という概念について混乱するかもしれない。患者は「有病」または「有病でない」のいずれかでしかあり得ない。であれば、「検査結果が陽性の患者が有病な確率は \(15\%\)」という文章は何を意味するのだろうか?
こういった文章の単純な解釈として「検査結果が陽性の患者全体の \(15\%\) が有病」がある。特定の患者を考えれば「有病」または「有病でない」が決定するものの、検査結果が陽性の患者の中からランダムに選択された人物が有病な確率は考えることができる。
しかし、\(15\%\) という確率は陽性の検査結果を受け取った患者個人に何を伝えるのだろうか? 乳癌があるのは約 \(7\) 回に \(1\) 回だと喜ぶべきだろうか? 約 \(7\) 回に \(1\) 回は乳癌があると心配するべきだろうか? 念のため治療を始めるべきだろうか? さらに検査を受けるべきだろうか?
これらはどれも現実的な疑問であるものの、統計を利用した行動決定や確率の哲学的な意味に関する問題であって、数学的な疑問ではない事実を理解することは重要である。この点についてさらに議論する前に、もう一つ「事実に関する確率」の例を見る。
ホッケーチームの勝率: 逆向き
第 18.3 節で考えた \(2\) 本先取のシリーズに出場するホッケーチームの問題をもう一度考えよう。今回は「チームがシリーズに勝利したという条件の下で、チームが最初の試合に勝利した確率」を考える。
先述した理由で、この確率が意味をなさないと考える人もいるだろう。チームがシリーズに勝利しているなら、最初の試合はとっくに終わっている。その試合に勝ったかどうかは確率ではなく事実に関する疑問である。しかし、これまでに説明してきた確率の数学的理論では、事象間に時間的な前後関係が存在しない。そもそも時間の概念が全く定義されない。さらに、この種の「過去の」事象に関する確率が現実で意味を持つこともある: チームがシリーズに勝利した事実だけを知っていて個別の試合結果を知らないとき、チームが最初の試合に勝った可能性はどれくらいだろうかと考えることは何もおかしくない。
事象 \(B\) が事象 \(A\) より先に起こるとき、条件付き確率 \(\operatorname{Pr}[B \, | \, A]\) を事後確率 (a posteriori probability) と呼ぶ。事後確率の例をいくつか示す:
-
ある日の午後に雨が降ったという条件の下で、その日の午前が曇りだった確率
-
ノーリミットのテキサス・ホールデムで、最終的な手がフォーカードだったという条件の元で、最初の手札に \(2\) 枚のクイーンが含まれていた確率
事後確率と通常の条件付き確率に数学的な違いがあるわけではない。確率を考える視点が違うだけであり、数学ではなく哲学のために用意された概念と言える。
先ほどの問題に戻ろう。第 18.3 節と同様に、\(A\) をチームがシリーズに勝利する事象、\(B\) をチームが最初の試合に勝つ事象とする。チームがシリーズに勝利したという条件の下でチームが最初の試合に勝利した確率は \(\operatorname{Pr}[B \, | \, A]\) の形をした事後確率であり、その値は条件付き確率の定義と樹形図 (図 \(\text{18.1}\)) から計算できる:
\[ \operatorname{Pr} [B \, | \, A] = \frac{\operatorname{Pr} [B \cap A]}{\operatorname{Pr}[A]} = \frac{1/3 + 1/18}{1/3 + 1/18 + 1/9} = \frac{7}{9} \]
一般に、事後確率の計算では次の規則がよく利用される:
定理 18.4.1[Bayes 則 (Bayes' rule)]
\[ \operatorname{Pr}[B \, | \, A] = \frac{\operatorname{Pr}[A \, | \, B] \cdot \operatorname{Pr} [B]}{\operatorname{Pr}[A]} \tag{18.2}\]
証明 条件付き確率の定義 (定義 18.2.1) より、次の等式を得る:
\[ \operatorname{Pr} [B \, | \, A] \cdot \operatorname{Pr} [A] = \operatorname{Pr} [A \cap B] = \operatorname{Pr} [A \, | \, B] \cdot \operatorname{Pr} [B] \]
両端の式を \(\operatorname{Pr}[A]\) で割れば等式 \(\text{(18.2)}\) が分かる。 ■
18.4.6 確率の哲学
次の事象 \(E\) に確率を割り当ててみよう:
非常に大きい整数の素数判定は自明でないので、素数の密度を使った推定が使えると思うかもしれない。素数定理によると \(2^{26972607} - 1\) 付近では約 \(500{,}000{,}000\) 個に \(1\) 個の整数が素数なので、そう考える人は \(E\) の確率を \(2 \cdot 10^{-8}\) に設定する。一方、数学の教科書で「確率の哲学」などと銘打つ項で使われる例なのだから、著者らが素数表から巨大な素数を取ってきた可能性が大いにあると考える人もいるかもしれない。そういった人は \(E\) の確率に \(1/2\) を割り当ててもおかしくない。最後に、\(E\) にはランダム性が全く関与しないので、\(E\) の確率を考える意味はないという立場を取ることもできる: \(2^{26972607} - 1\) は素数か合成数かのいずれかに必ず定まる。本書が採用するのは最後の考え方である。
これとは異なる考え方として、確率が命題の成立に関する信念の度合いを表すと解釈する Bayes 主義 (Bayesian) のアプローチがある。Bayes 主義者は上記の整数が素数か合成数かのどちらかである点には同意する一方で、両方の可能性に確率を割り当てることには何も問題がないと考える。ベイズ主義のアプローチでは任意の事象に確率を割り当てられるために適用範囲が非常に広い一方で、事象に対する「正しい」確率が存在しなくなることが問題になる ── 個人的な考え・信念が確率に影響を及ぼすからである。一方で、自信を持って最初に採用する信念を選択できるなら、Bayes 主義のアプローチは新たな情報が得られるたびに信念を更新する数学的なフレームワークを提供する。
余談: Bayes 自身がここに説明した意味で Bayes 主義者だったかどうかは分からない。しかし、Bayes 主義者は Bayes が Bayes 主義者だった確率について喜んで考えるだろう。
さらに別の流派の人々は、確率は「サイコロを振る」や「コインを投げる」といった反復可能な処理に対してだけ意味を持って定義できる概念だと主張する。この頻度主義 (frequentist) と呼ばれる考え方では、試行を何度も繰り返したときに特定の事象が発生する試行の割合がその事象の確率とみなされる。第 18.4.5 項で触れたホッケーチームを使った事後確率の例は次のように解釈される: 「チームがシリーズに勝利したという条件の下で、チームが最初の試合に勝利した確率」とは、「シリーズを戦う」という試行を何度も繰り返したとき、チームがシリーズに勝利する試行全体の集合に含まれる最初の試合に勝利する試行の割合に等しい。
素数に話を戻そう。第 9.5.1 項で触れたように、確率的な素数判定法が存在する。\(N\) が合成数なら、この判定法は少なくとも \(3/4\) の確率で「合成数である」と出力する。この出力が得られない確率 \(1/4\) 以下の状況では、判定法は解答を出せない。しかし、この判定法は解答が得られないとき独立して何度でも繰り返すことができる。そのため、例えば判定法を \(100\) 回繰り返すとき合成数 \(N\) が合成数であることを見抜けない確率は次の値より小さくなる:
\[ \left( \frac{1}{4} \right)^{\! 100} \]
判定法を \(100\) 回実行した後でも、理論上は \(N\) が合成数である可能性が残されている。しかし、\(N\) が素数であることに金を賭けるのは人生で最も安全な賭けとなる! こういった試行の後にあなたが抱く個人的な信念を確率として表現することに違和感を覚えないなら、あなたはベイズ主義者である。頻度主義者は \(N\) の素数性に確率を割り当てようとはしないだろう。ただ、彼らも全幅の信頼 (confidence) を持って \(N\) が素数でないことに金を賭けるのは間違いない。この話題は標本抽出と信頼水準を議論する第 18.9 節でまた触れる。
こういった哲学的分断はあるものの、ベイズ主義者と頻度主義者が確率を解釈して得る現実の問題に対する結論は同じである場合が多い。さらに、たとえ解釈が一致しない場合でも、利用される確率の理論に違いはない。
-
本項の例は実際の医療データを大まかに参考にしているものの、計算が簡単になるように数字を改変している。 ↩︎